In 1984, a panel at the AAAI conference discussed whether the field was approaching an "AI Winter". Mitch Waldrop wrote a transcript of the discussion, and much of it reads exactly like something written 35 years into the future.
Below are some quotes from the transcript that I found impressive, as they describe the feelings of many an AI researcher today and how the public views AI, despite all the advances in computing and software since 1984. 👇
"People make essentially no distinction between computers, broadly defined, and Artificial Intelligence... as far as they're concerned, there is no difference; they're just worried about the impact of very capable, smart computers" - Mitch Waldrop
"The computer is not only a mythic emblem for this bright, high-technology future, it's a mythic symbol for much of the anxiety that people have about their own society." - Mitch Waldrop
"A second anxiety, what you might call the 'Frankenstein Anxiety', is the fear of being replaced, of becoming superfluous..." - Mitch Waldrop
"Modern Times Anxiety: People becoming somehow, because of computers, just a cog in the vast, faceless machine; the strong sense of helplessness, that we really have no control over our lives" - Mitch Waldrop
"The problem is not a matter of imminent deadlines or lack of space or lack of time... the real problem is that what reporters see as real issues in the world are very different from what the AI community sees as real issues." - Mitch Waldrop
"If we expect physicists to be concerned about arms control and chemists to be concerned about toxic waste, it's probably reasonble to expect AI people to be concerned about the human impact of these technologies" - Mitch Waldrop
"It [Doomsday] is already here. There is no content in this conference" - Bob Wilensky
"What I heard was that only completed scientific work was going to be accepted. This is a horrible concept - no new unformed ideas, no incremental work building on previous work" - Roger Schank
"When I first got into this field twenty years ago, I used to explain to people what I did, and they would already say, 'you mean computers can't do that already?' They'll always believe that." - Roger Schank
"Big business has a very serious role in this country. Among other things, they get to determine what's 'in' and what's 'out' in the government." - Roger Schank
"I got scared when big business started getting into this - Schlumberger, Xerox, HP, Texas Instruments, GTE, Amico, Exxcon, they were all making investments - they all have AI groups. And you find out that, thoise people weren't trained in AI." - Roger Schank
"It's easier to go into a startup... [or] a big company... than to go into a university and try to organize an AI lab, which is just as hard to do now as it ever was. But if we don't do that, we will find that we are in the 'Dark Ages' of AI" - Roger Schank
"The first [message] is incumbent upon AI because we have promised so much, to produce. We must produce working systems. Some of you must devote yourselves to doing that. It is also the case that some of you had better commit to doing science." - Roger Schank
"If it turns out that our AI conference isn't the place to discuss science, then we better start finding a place where we can discuss science, because this show for all the venture capitalists is very nice." - Roger Schank
"the notion of cognition as computation is going to have extraordinary importance to the philosophy and psychology of the next generation. And for well or ill, this notion has affected some of the deepest aspects of our self-image." - B. Chandrasekaran
"symbol-level theories, which may even be right, are being mistaken for knowledge-level theories" - B. Chandrasekaran
"My hope is that AI will evolve more like biotech in the sense that certain technologies will be spun off, and researchers will remain and extremely interesting progress will be made" - B. Chandrasekaran
"I have encountered people who have a science fiction view of the world and think that computers now can do just about anything... these people have a feeling that computers can do wonderful things, but if you ask them how exactly could an AI program help in work, they don't have the sense that within a week or two they could be replaced or that computers can come in and do a much better job than they do in work." - John McDermott
"There have been a number of technologies that have run into dead ends, like dirigibles and external combustion engines. And there have been other ones, like television, and in fact, the telephone system itself, which took between twenty and forty years to go from being laboratory possibilities to actual commercial successes. Do you really think that AI is going to become a commercial success in the next 10-15 years?" - Audience member
"They [lay people] seem to have a vague idea that great things can happen, have sublime confidence... but when it gets down to the nitty-gritty, they tend to be pretty unimaginative and have pretty low expectations as to what can be done." - Mitch Waldrop
"It seems that academic AI people tend to blame everyone but themselves when it comes to problems of AI in terms of relationship to the general society." - Audience member
Wednesday, December 25, 2019
Thursday, November 28, 2019
Differentiable Path Tracing on the GPU/TPU
You can download a PDF (typset in LaTeX) of this blog post here.
Jupyter Notebook Code on GitHub: https://github.com/ericjang/pt-jax

This blog post is a tutorial on implementing path tracing, a physically-based rendering algorithm, in JAX. This code runs on the CPU, GPU, and Google Cloud TPU, and is implemented in a way that also makes it end-to-end differentiable. You can compute gradients of the rendered pixels with respect to geometry, materials, whatever your heart desires.
I love JAX because it is equally suited for pedagogy and high-performance computing. We will implement a path tracer for a single pixel in numpy-like syntax, slap a jax.vmap operator on it, and JAX automatically converts our code to render multiple pixels with SIMD instructions! You can do the same thing for multiple devices using jax.pmap. If that isn't magic, I don't know what is. At the end of the tutorial you will not only know how to render a Cornell Box, but also understand geometric optics and radiometry from first principles.
The figure below, borrowed from a previous post from this blog, explains at a high level the light simulator we're about to implement:

I divide this tutorial into two parts: 1) implementing geometry-related functions like ray-scene intersection and normal estimation, and 2) the "light transport" part where we discuss how to accumulate radiance arriving at an imaginary camera sensor.
JAX and Matplotlib (and a bit of calculus and probability) are the only required dependencies for this tutorial:
import jax.numpy as np
from jax import jit, grad, vmap, random, lax
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
JAX is essentially a drop-in replacement for numpy, with the exception that operations are all functional (no indexing assignment) and the user must manually pass around an explicit rng_key to generate random numbers. Here is a short list of JAX gotchas if you are coming to JAX as a numpy user.
Part I: Geometry
The vast majority of rendering software represents scene geometry as a collection of surface primitives that form "meshes". 3D modeling software form meshes using quadrilaterial faces, and then the rendering software converts the quads to triangles under the hood. Collections of meshes are composed together to form entire objects and scenes. For this tutorial we're going to use an unorthodox geometry representation and we'll need to implement a few helper functions to manipulate them.
Differentiable Scene Intersection with Distance Fields
Rendering requires computing intersection points $y$ in the scene with ray $\omega_i$, and usually involves traversing a highly-optimized spatial data structure called a bounding volume hierarchy (BVH). $y$ can be expressed as a parametric equation of the origin point $x$ and raytracing direction $\omega_i$, and the goal is to find the distance $t$:
$\hat{y} = x + t \cdot \omega_i$
There is usually a lot of branching logic in BVH traversal algorithms, which makes it harder to implement efficiently on accelerator hardware like GPUs and TPUs. Instead, let's use raymarching on signed distance fields to find the intersection point $y$. I first learned of this geometry modeling technique when Inigo "IQ" Quilez, a veritable wizard of graphics programming, gave a live coding demo at Pixar about how he modeled vegetation in the "Brave" movie. Raymarching is the primary technique used by the ShaderToy.com community to implement cool 3D movies using only instructions available to WebGL fragment shaders.
A signed distance field over position $p$ specifies "the distance you can move in any direction without coming into contact with the object". For example, here is the signed distance field for a plane that passes through the origin and is perpendicular to the y-axis.
def sdFloor(p):
return p.y
To find the intersection distance $t$, the raymarching algorithm iteratively increments $t$ by step sizes equal to the signed distance field of the scene (so we never pass through an object). This iteration happens until $t$ "leaves the scene'" or the distance field shrinks to zero (we have collided with an object). For the plane distance, we see from the diagram below that stepping forward using the distance field allows us to get arbitrarily close to the plane without ever passing through it.

def raymarch(ro, rd, sdf_fn, max_steps=10):
t = 0.0
for i in range(max_steps):
p = ro + t*rd
t = t + sdf_fn(p)
return t
Signed distance fields combined with raymarching have a number of nice mathematical properties. The most important one is that unlike analytical ray-shape intersection, raymarching does not require re-deriving an analytical solution for intersecting points for every primitive shape we wish to add to the scene. Triangles are also general, but they require a lot of memory to store expressive scenes. In my opinion, signed distance fields strike a good balance between memory budget and geometric expressiveness.
Similar to ResNet architectures in Deep Learning, the raymarching algorithm is a form of "unrolled iterative inference" of the same signed distance field. If we are trying to differentiate through the signed distance function (for instance, trying to approximate it with a neural network), this representation may be favorable to gradient descent algorithms.
Building Up Our Scene
The first step is to implement the signed distance field for the scene of interest. The naming and programming conventions in this tutorial are heavily inspired by stylistic conventions used by ShaderToy DemoScene community. One such convention is to define hard-coded enums for each object, so we can associate intersection points to their nearest object. The values are arbitrary; you can substitute them with your favorite numbers if you like.
OBJ_NONE=0.0
OBJ_FLOOR=0.1
OBJ_CEIL=.2
OBJ_WALL_RD=.3
OBJ_WALL_WH=.4
OBJ_WALL_GR=.5
OBJ_SHORT_BLOCK=.6
OBJ_TALL_BLOCK=.7
OBJ_LIGHT=1.0
OBJ_SPHERE=0.9
Computing a ray-scene intersection should therefore return an object id and an associated distance, for which we define a helper function to zip up those two numbers.
def df(obj_id, dist):
return np.array([obj_id, dist])
Next, we'll define the distance field for a box (source: https://www.iquilezles.org/www/articles/distfunctions/distfunctions.htm).
def udBox(p, b):
# b = half-widths
return length(np.maximum(np.abs(p)-b,0.0))
Rotating, translating, and scaling an object implied by a signed distance field is done by performing the inverse operation to the input point to the distance function. For example, if we want to rotate one of the boxes in the scene by an angle of $\theta$, we rotate its argument $p$ by $-\theta$ instead.
def rotateX(p,a):
# We won't be using rotateX for this tutorial.
c = np.cos(a); s = np.sin(a);
px,py,pz=p[0],p[1],p[2]
return np.array([px,c*py-s*pz,s*py+c*pz])
def rotateY(p,a):
c = np.cos(a); s = np.sin(a);
px,py,pz=p[0],p[1],p[2]
return np.array([c*px+s*pz,py,-s*px+c*pz])
def rotateZ(p,a):
c = np.cos(a); s = np.sin(a);
px,py,pz=p[0],p[1],p[2]
return np.array([c*px-s*py,s*px+c*py,pz])
Another cool property of signed distance fields is that you can compute the union of two solids with a simple np.minimum operation. By the definition of a distance field, if you take a step size equal to the smaller of the two distances in either direction, you are still guaranteed not to intersect with anything. The following method, short for "Union Operation", joins to distance fields by comparing their distance property.
def opU(a,b):
if a[1] < b[1]:
return a
else:
return b
Unfortunately, the JAX compiler complains when combining both grad and jit operators through conditional logic like the one above. So we need to write things a little differently to preserve differentiability:
def opU(a,b):
condition = np.tile(a[1,None]<b[1,None], [2])
return np.where(condition, a, b)
Now we have all the requisite pieces to build the signed distance field for the Cornell Box, which we call sdScene. Recall from the previous section that the distance field for an axis-aligned plane is just the height along that axis. We can use this principle to build infinite planes that comprise the walls, floor, and ceiling of the Cornell Box.
def sdScene(p):
# p is [3,]
px,py,pz=p[0],p[1],p[2]
# floor
obj_floor = df(OBJ_FLOOR, py) # py = distance from y=0
res = obj_floor
# ceiling
obj_ceil = df(OBJ_CEIL, 4.-py)
res = opU(res,obj_ceil)
# backwall
obj_bwall = df(OBJ_WALL_WH, 4.-pz)
res = opU(res,obj_bwall)
# leftwall
obj_lwall = df(OBJ_WALL_RD, px-(-2))
res = opU(res,obj_lwall)
# rightwall
obj_rwall = df(OBJ_WALL_GR, 2-px)
res = opU(res,obj_rwall)
# light
obj_light = df(OBJ_LIGHT, udBox(p - np.array([0,3.9,2]), np.array([.5,.01,.5])))
res = opU(res,obj_light)
# tall block
bh = 1.3
p2 = rotateY(p- np.array([-.64,bh,2.6]),.15*np.pi)
d = udBox(p2, np.array([.6,bh,.6]))
obj_tall_block = df(OBJ_TALL_BLOCK, d)
res = opU(res,obj_tall_block)
# short block
bw = .6
p2 = rotateY(p- np.array([.65,bw,1.7]),-.1*np.pi)
d = udBox(p2, np.array([bw,bw,bw]))
obj_short_block = df(OBJ_SHORT_BLOCK, d)
res = opU(res,obj_short_block)
return res
Notice that we model the light source on the ceiling as a rectangular prism with half-widths $(0.5, 0.5)$. All numbers are expressed in SI units, so this implies a 1 meter x 1 meter light, and a big 4m x 4m Cornell box (this is a big scene!). The size of the light will become relevant later when we compute quantitites like emitted radiance.
Computing Surface Normals
In rendering we need to frequently compute the normals of geometric surfaces. In ShaderToy programs, the most common algorithm used to compute normals is a finite-difference gradient approximation of the distance field $\nabla_p d(p)$, and then normalize that vector to obtain an approximate normal.
def calcNormalFiniteDifference(p):
# derivative approximation via midpoint rule
eps = 0.001
dx=np.array([eps,0,0])
dy=np.array([0,eps,0])
dz=np.array([0,0,eps])
# extract just the distance component
nor = np.array([
sdScene(p+dx) - sdScene(p-dx),
sdScene(p+dy) - sdScene(p-dy),
sdScene(p+dz) - sdScene(p-dz),
])
return normalize(nor)
Note that this requires six separate evaluations to the sdScene function! As it turns out, JAX can give us analytical normals basically for free via its auto-differentiation capabilities. The backward pass has the same computational complexity as the forward pass, resulting in autodiff gradients being 6x faster than finite-differencing. Neat!
def dist(p):
# return the distance-component only
return sdScene(p)[1]
def calcNormalWithAutograd(p):
return normalize(grad(dist)(p))
Cosine-Weighted Sampling
We require is the ability to sample scattering rays around some local surface normal, for when we choose recursive rays to scatter. All the objects in the scene are assigned "Lambertian BRDFs'', which mean that they are matte in reflectance properties and the apparent brightness to an observer is the same regardless of viewing angle. For Lambertian materials, it is much more effective to sample from a cosine-weighted distribution because it allows two cosine-related probability terms (from the sampling and from the BRDF) to cancel out. The motivation for this will become apparent in Part II of the tutorial, but here is the code up front.
def sampleCosineWeightedHemisphere(rng_key, n):
rng_key, subkey = random.split(rng_key)
u = random.uniform(subkey,shape=(2,),minval=0,maxval=1)
u1, u2 = u[0], u[1]
uu = normalize(np.cross(n, np.array([0.,1.,1.])))
vv = np.cross(uu,n)
ra = np.sqrt(u2)
rx = ra*np.cos(2*np.pi*u1)
ry = ra*np.sin(2*np.pi*u1)
rz = np.sqrt(1.-u2)
rr = rx*uu+ry*vv+rz*n
return normalize(rr)
Here's a quick 3D visualization to see whether our implementation is doing something reasonable:
from mpl_toolkits.mplot3d import Axes3D
nor = normalize(np.array([[1.,1.,0.]]))
nor = np.tile(nor,[1000,1])
rng_key = random.split(RNG_KEY, 1000)
rd = vmap(sampleCosineWeightedHemisphere)(rng_key, nor)
fig = plt.figure()
ax = fig.add_subplot(121, projection='3d')
ax.scatter(rd[:,0],rd[:,2],rd[:,1])
ax = fig.add_subplot(122)
ax.scatter(rd[:,0],rd[:,1])

Camera Model
For each pixel we want to render, we need to associate it with a ray direction rd and a ray origin ro. The most basic camera model for computer graphics is a pinhole camera, shown below:

The following code sets up a pinhole camera with focal distance of 2.2 meters:
N=150 # width of image plane
xs=np.linspace(0,1,N) # 10 pixels
us,vs = np.meshgrid(xs,xs)
uv = np.vstack([us.flatten(),vs.flatten()]).T
# normalize pixel locations to -1,1
p = np.concatenate([-1+2*uv, np.zeros((N*N,1))], axis=1)
# Render a pinhole camera.
eye = np.tile(np.array([0,2.,-3.5]),[p.shape[0],1])
look = np.array([[0,2.0,0]]) # look straight ahead
w = vmap(normalize)(look - eye)
up = np.array([[0,1,0]]) # up axis of world
u = vmap(normalize)(np.cross(w,up))
v = vmap(normalize)(np.cross(u,w))
d=2.2 # focal distance
rd = vmap(normalize)(p[:,0,None]*u + p[:,1,None]*v + d*w)
If you wanted to render an orthographic projection, you can simply set all ray direction values to point straight forward along the Z-axis, instead of all originating from the same eye point: rd = np.array([0, 0, 1]).
N=150 # width of image plane
xs=np.linspace(0,1,N) # 10 pixels
us,vs = np.meshgrid(xs,xs)
us = (2*us-1)
vs *= 2
uv = np.vstack([us.flatten(),vs.flatten()]).T # 10x10 image grid
eye = np.concatenate([uv, np.zeros((N*N,1))], axis=1)*2
rd = np.zeros_like(eye) + np.array([[0, 0, 1]])
An orthographic camera is what happens when you stretch the focal distance to infinity. That will yield an image like this:

Part II: Light Simulation
With our scene defined and basic geometric functions set up, we can finally get to the fun part of implementing light transport. This part of the tutorial is agnostic to the geometry representation described in Part I, so you can actually follow along with whatever programming language and geometry representation you like (raymarching, triangles, etc).
Radiometry From First Principles
Before we learn the path tracing algorithm, it is illuminating to first understand the underlying physical phenomena being simulated. Radiometry is a mathematical framework for measuring electromagnetic radiation. Not only can it be used to render pretty pictures, but it can also be used to understand heat and energy propagated in straight lines within closed systems (e.g. blackbody radiation). What we are ultimately interested in are human perceptual color quantities, but to get them first we will simulate the physical quantities (Watts) and then convert them to lumens and RGB values.
This section borrows some figures from the PBRT webpage on Radiometry. I highly recommend reading that page before proceeding, but I also summarize the main points you need to know here.
You can actually derive the laws of radiometry from first principles, using only the principle of conservation of energy: within a closed system, the total amount of energy being emitted is equal to the total amount of energy being absorbed.
Consider a small sphere of radius $r$ emitting 60 Watts of electromagnetic power into a larger enclosing sphere of radius $R$. We know that the bigger sphere must be absorbing 60 Watts of energy, but because it has a larger surface area ($4\pi R^2$), the incoming energy density per unit area is a factor of $\frac{R^2}{r^2}$ smaller.
We call this "area density of flux'' irradiance (abbreviated $E$) if it is arriving at a surface, and radiant exitance (abbreviated $M$) if it is leaving a surface. The SI unit for these quantities are Watts per square meter.
 |
| Figure Source: http://www.pbr-book.org/3ed-2018/Color_and_Radiometry/Radiometry.html |
Now let's consider a slightly different scene in the figure below, where a small flat surface with area $A$ emits a straight beam of light onto the floor. On the left, the emitting and receiving surfaces have the same area, $A = A_1$, so the irradiance equals radiant exitance $E = M$. On the right, the beam of light shines on the floor at an angle $\theta$, which causes the projection $A_2$ to be larger. Calculus and trigonometry tell us that as we shrink the area $A \to 0$, the area of the projected light $A_2$ approaches $\frac{A}{\cos \theta}$. Because flux must be conserved, the irradiance of $A_2$ must be $E = M \cos \theta$, where $\theta$ is the angle between the surface normal and light direction. This is known as "Lambert's Law''.
 |
| Figure Source: http://www.pbr-book.org/3ed-2018/Color_and_Radiometry/Radiometry.html |
In the above examples, the scenes were simple or symmetric enough that we did not have to think about what direction light is coming from when computing the irradiance of a surface. However, if we want to simulate light in a complex scene, we will need to compute irradiance by integrating light over many possible directions. For non-transparent surfaces, this set of directions forms a hemisphere surrounding the point of interest, and is perpendicular to the surface normal.
Radiance extends the measure of irradiance to also depend on the solid angle of incident light. Solid angles are just extensions of 2D angles to 3D spheres (and hemispheres). You can recover irradiance and power by integrating out angle and area of irradiance, respectively:
- Radiance $L = \frac{\partial^2 \Phi}{\partial \Omega \partial A \cos \theta}$ measures flux per projected unit area $A \cos \theta$ per unit solid angle (Figure 5.10) $\Omega$.
- Irradiance $E = \frac{\partial \Phi}{\partial A \cos \theta}$ is the integral of radiance over solid angles $\Omega$.
- Power $\Phi$ is the integral of irradiance over projected area $A$.
A nice property of radiance is that it is conserved along rays through empty space. We have the incoming radiance $L_i$ from direction $\omega_i$ to point $x$ equal to the outgoing radiance $L_o$ from some other point $y$, in the reverse direction $-\omega_i$. $y$ is the intersection of origin $x$ along ray $\omega_i$ with the scene geometry.
$ L_i(x, \omega_i) = L_o(y, -\omega_i) $
It's important to note that although incoming and outgoing radiance are conserved along empty space, we still need to respect Lambert's Law when computing an irradiance at a surface.
Different Ways to Integrate Radiance
You may remember from calculus class that it is sometimes easier to compute integrals by changing the integration variable. The same concept holds in rendering: we'll use three different integration methods in building a computationally efficient path tracer. In this section I will draw some material directly from the PBRTv3 online textbook, which you can find here: http://www.pbr-book.org/3ed-2018/Color_and_Radiometry/Working_with_Radiometric_Integrals.html
I was a teaching assistant for the graduate graphics course for 2 years at Brown and by far the most common mistake made in the path tracing project assignments were insufficient understanding of the calculus that went into correctly integrating radiometric quantities.
Integrating Over Solid Angle
As mentioned before, in order to compute irradiance $E(x, n)$ at a surface point $x$ with normal $n$, we need to take Lambert's rule into account, because there is a "spreading out'' of flux density that occurs when light sources are facing at an angle.
$E(x, n) = \int_\Omega d\omega L_i(x, \omega) |\cos \theta| = \int_\Omega d\omega L_i(x, \omega) |\omega \cdot n| $
One way to estimate this integral is a single-sample Monte Carlo Estimator, where we sample a single ray direction $\omega_i$ uniformly from the hemisphere, and evaluate the radiance for that direction. In expectation over $\omega_i$, the estimator computes the correct integral.
$\omega_i \sim \Omega $
$\hat{E}(x, n) = L_i(x, \omega_i) |\omega \cdot n| \frac{1}{p(\omega_i)} $
Integrating Over Projected Solid Angle
Due to Lambert's law, we should never sample outgoing rays perpendicular to the surface normal because the projected area $\frac{A}{\cos \theta}$ approaches infinity, so the radiance contribution to that area is zero.
We can avoid sampling these "wasted'' rays by weighting the probability of sampling a ray according to Lambert's law - in other words, a cosine-weighted distribution $H^2$ along the hemisphere. This requires us to perform a change of variables, and integrate with respect to the projected solid angle $d\omega^\perp = |\cos \theta| d\omega$.
This is where the cosine-weighted hemisphere sampling function we implemented earlier will come in handy.
$ E(x, n) = \int_{H^2} d\omega^\perp L_i(x, \omega^\perp) $
The cosine term in the integral means that the contribution to irradiance is higher as the light source becomes more perpendicular to the light.
Integrating Over Light Area
If the light source subtends a very small solid angle on the hemisphere, we will need to sample a lot of random outgoing rays before we find one that intersects the light source. For small or directional light sources, it is far more computationally efficient to integrate over the area of the light, rather than the hemisphere.
 |
| Figure Source: http://www.pbr-book.org/3ed-2018/Color_and_Radiometry/Working_with_Radiometric_Integrals.html |
If we perform a change in variables from differential solid angle $d\omega$ to differential area $dA$, we must compensate for the change in volume.
$ d\omega = \frac{dA \cos \theta_o}{r^2} $
I won't go through the derivation in this tutorial, but the interested reader can find it here: https://www.cs.princeton.edu/courses/archive/fall10/cos526/papers/zimmerman98.pdf. Substituting the above equation into the irradiance integral, we have:
$ E(x, n) = \int_{A} L \cos \theta_i \frac{dA \cos \theta_o}{r^2} $
where $L$ is the emitted radiance of the light coming from the implied direction $-\omega$, which has an angular offset of $\theta_o$ from the light surface's surface normal. The corresponding single-sample Monte Carlo estimator is given by sampling a point on the area light, rather than a direction on the hemisphere. The probability $p(p)$ of sampling the point $p$ on an area $A$ is usually given by a uniform $\frac{1}{A}$.
$p \sim A $
$\omega = \frac{p-x}{\left\lVert {p-x} \right\rVert} $
$r^2 = \left\lVert {p-x} \right\rVert ^2 $
$\hat{E}(x, n) = \frac{1}{p(p)}\frac{L}{r^2} |\omega \cdot x| |-\omega \cdot n| $
Making Rendering Computationally Tractable with Path Integrals
The rendering equation describes the outgoing radiance $L_o(x, \omega_o)$ from point $x$ along ray $\omega_o$.
$ L_o(x, \omega_o) = L_e(x, \omega_o) + \int_{\Omega} f_r(x, \omega_i, \omega_o) L_i(x, \omega_i) (-\omega_i \cdot n) d\omega_i $
where $L_e(x, \omega_o)$ is emitted radiance, $f_r(x, \omega_i, \omega_o)$ is the BRDF (material properties), $L_i(x, \omega_i)$ is incoming radiance, $(-\omega_i \cdot n)$ is the attenuation of light coming in at an incident angle with surface normal $n$. The integral is with respect to solid angle on a hemisphere.
How do we go about implementing this on a computer? Evaluating the incoming light to a point requires integrating over an infinite number of directions, and for each of these directions, we have to recursively evaluate the incoming light to those points. Our computers simply cannot do this.
Fortunately, path tracing provides a tractable way to approximate this scary integral. Instead of integrating over the hemisphere $\Omega$, we can sample a random direction $w_i \sim \Omega$, and the probability-weighted contribution from that single ray is an unbiased, single-sample monte carlo estimator for Eq. 1.
$ \omega_i \sim \Omega $
$\hat{L}_o(x, \omega_o) = L_e(x, \omega_o) + \frac{1}{p(\omega_i)} f_r(x, \omega_i, \omega_o) L_i(x, \omega_i) (-\omega_i \cdot n(x)) $
We still need to deal with infinite recursion. In most real-world scenarios, a photon only bounces around a few times before it is absorbed, so we can truncate the depth or use a more unbiased technique like Russian Roulette sampling. We recursively trace the $L_i(x, \omega_i)$ function until we hit the termination condition, which results in a linear computation cost with respect to depth.
A Naive Path Tracer
Below is the code for a naive path tracer, which is more or less a direct translation of the equation above.
def trace(ro, rd, depth):
p = intersect(ro, rd)
n = calcNormal(p)
radiance = emittedRadiance(p, ro)
if depth < 3:
# Uniform hemisphere sampling
rd2 = sampleUniformHemisphere(n)
Li = trace(p, rd2, depth+1)
radiance += brdf(p, rd, rd2)*Li*np.dot(rd, n)
return radiance
We assume a 25 Watt square light fixture at the top of the Cornell Box that acts as a diffuse area light and only emits light from one side of the plane. Diffuse lights have uniform spatial and directional radiance distribution; this is also known as a "Lambertian Emitter'', and it has a closed-form solution for its emitted radiance from any direction:
LIGHT_POWER = np.array([25, 25, 25]) # Watts
LIGHT_AREA = 1.
def emittedRadiance(p, ro):
return LIGHT_POWER / (np.pi * LIGHT_AREA)
The $\pi$ term is a little surprising at first, but you can find the derivation here for where it comes from: https://computergraphics.stackexchange.com/questions/3621/total-emitted-power-of-diffuse-area-light.
Normally we'd have to track radiance for every visible wavelength, but we can obtain a good approximation of the entire spectral power distribution by tracking radiance for just a few wavelengths of light. According to tristimulus theory, it is actually possible to represent all human-perceivable colors with 3 numbers, such as XYZ or RGB color bases. For simplicity, we'll only compute radiance values for R, G, B wavelengths in this tutorial. The brdf term corresponds to material properties. This is a simple scene in which all materials are Lambertian, meaning that the direction of the incident and exitant angles don't matter, so the brdf reflects incident radiance by multiplying its R, G, B values. Here are the BRDFs we use for various objects in the scene, expressed in the RGB basis:
lightDiffuseColor = np.array([0.2,0.2,0.2])
leftWallColor = np.array([.611, .0555, .062]) * 1.5
rightWallColor = np.array([.117, .4125, .115]) * 1.5
whiteWallColor = np.array([255, 239, 196]) / 255
We can make our path tracer more efficient by switching the integration variable to the projected solid angle $d\omega_i |\cos \theta|$. As discussed in the last section, this has the benefit of importance-sampling the solid angles that are proportionally larger due to Lambert's law, and as an added bonus we can drop the evaluation of the cosine term.
def trace(ro, rd, depth):
p = intersect(ro, rd)
n = calcNormal(p)
radiance = emittedRadiance(p, ro)
if depth < 3:
# Cosine-weighted hemisphere sampling
rd2 = sampleCosineWeightedHemisphere(n)
Li = trace(p, rd2, depth+1)
radiance += brdf(p, rd, rd2)*Li
return radiance
Reducing Variance by Splitting Up Indirect Lighting
The above estimator is correct and will get you the right result in expectation, but ends up being a high-variance estimator because the samples only have nonzero radiance when one or more of the path intersections intersects the emissive geometry. If you are trying to render a scene that is illuminated by a geometrically small light source -- a candle in a dark room perhaps -- the vast majority of path samples will never intersect the candle, and subsequently these samples will be sort of wasted. The image will appear very grainy and dark.
Luckily, the area integration trick we discussed a few sections back comes to our rescue. In graphics, we actually know where the light surfaces are ahead of time, so we can integrate over the emissive surface instead of integrating over the receiving surface's solid angles. We do this by performing a change of variables $d\omega = \frac{dA \cos \theta_o}{r^2}$.
To implement this trick, we can split up indirect lighting reflecting off point $p$ into two separate calculations: (1) direct lighting a the light source bouncing off of $p$, and (2) indirect lighting from a non-light source reflecting off of $p$. Notice that we have to modify the recursive trace term to ignore emittedRadiance from any lights it encounters, except for the case where light leaves the emitter and enters the eye directly (which is when depth=0). This is because for each point $p$ in the path, we are already accounting for an extra path that goes from an area light directly to $p$. We don't want to double count such paths!
def trace(ro, rd, depth):
p = intersect(ro, rd)
n = calcNormal(p)
if depth == 0:
# Integration over solid angle (eye ray)
radiance = emittedRadiance(p, ro)
# Direct Lighting Term
pA, M, pdf_A = sampleAreaLight()
n_light = calcNormal(pA)
if visibilityTest(p, pA):
square_distance = np.sum(np.square(pA - p))
w_i = normalize(pA - p)
dw_da = np.dot(n_light, -w_i)/square_distance # dw/dA
radiance += (brdf(p, rd, w_i) * np.dot(n, w_i) * M) * dw_da
# Indirect Lighting Term
if depth < 3:
# Integration over cosine-weighted solid angle
rd2 = sampleCosineWeightedHemisphere(n)
Li = trace(p, rd2, depth+1)
radiance += brdf(p, rd, rd2)*Li
return radiance
The sampleAreaLight() function samples a point $p$ on an area light with emitted radiance $M$ and also computes the probability of choosing that sample (for a uniform emitter, it's just one over the area).
The cool thing about this path tracer implementation is that it features three different ways to integrate irradiance: solid angles, projected solid angles, and area light surfaces. Calculus is useful!
Ignoring Photometry
Photometry is the study of how we convert radiometric quantities (the outputs of the path tracer) to the color quantities perceived by the human visual system. For this tutorial we will do a crude approximation of the radiometric-to-photometric by simply clipping the values of each R, G, B radiance to a maximum of 1, and display the result directly in matplotlib.
And voila! We get a beautifully path-traced image of a Cornell Box. Notice how colors from the walls "bleed" onto adjacent walls, and the shadows cast by the boxes are "soft".

Performance Benchmarks: P100 vs. TPUv2
Copying data between accelerators (TPU, GPU) and host chips (CPU) is very slow, so we'll try to compile the path tracing code into as few XLA calls from Python as possible. We can do this by applying the jax.jit operator to the entire trace() function, so the rendering happens completely on the accelerator. Because trace is a recursive function, we need to tell the XLA compiler that we are actually compiling it with a statically fixed depth of 3, so that XLA can unroll the loop and make it non-recursive. The vmap call then transforms the function into a vectorized version.
trace = jit(trace, static_argnums=(3,)) # optional
render_fn = lambda rng_key, ro, rd : trace(rng_key, ro, rd, 0)
vec_render_fn = vmap(render_fn)
According to jax.local_device_count(), a Google Cloud TPU has 8 cores. The code above only performs SIMD vectorization across 1 device, so we can also parallelize across multiple TPU cores using JAX's pmap operator to get an additional speed boost..
# vec_render_fn = vmap(render_fn)
vec_render_fn = jax.soft_pmap(render_fn)
How fast does this path tracer run? I benchmarked the performance of a (1) manually-vectorized Numpy implementation, (2) a vmap-vectorized single-pixel implementation, and (3) a manually-vectorized JAX implementation (almost identical in syntax to numpy). Jitting the recursive trace function was very slow to compile (occasionally even crashed my notebook kernel), so I also implemented a version where the recursion happens in Python but the loop body of trace (direct lighting, emission, sampling rays) are executed on the accelerator.
# vec_render_fn = vmap(render_fn)
vec_render_fn = jax.soft_pmap(render_fn)
How fast does this path tracer run? I benchmarked the performance of a (1) manually-vectorized Numpy implementation, (2) a vmap-vectorized single-pixel implementation, and (3) a manually-vectorized JAX implementation (almost identical in syntax to numpy). Jitting the recursive trace function was very slow to compile (occasionally even crashed my notebook kernel), so I also implemented a version where the recursion happens in Python but the loop body of trace (direct lighting, emission, sampling rays) are executed on the accelerator.
The plot below shows that JAX code is much slower to run on the first sample because the just-in-time compilation has to compile and fuse all the necessary XLA operations. I wouldn't read too carefully into this plot (especially when comparing GPU vs. TPU) because when I was doing these experiments I encountered a huge amount of variance in compile times. Numpy doesn't have any JIT compilation overhead, so it runs much faster for a single sample, even on the CPU.


What about a multi-sample render? After the XLA kernels have been compiled, subsequent calls to the trace function are very fast.

We see that there's a trade-off between compilation time and runtime: the more we compile, the faster things run when performing many samples. I haven't tuned the code to favor any accelerator in particular, and this is the first time I've measured TPU and GPU performance under a reasonable path tracing workload. Path tracing is an embarrassingly parallel workload (on the pixel level and image sample level), so it should be quite possible to get a linear speedup from using more TPU cores. My code currently does not do that because each pmap'ed worker is blocked on rendering an entire image sample. If you have suggestions on how to accelerate the code further, I'd love to hear from you.
Summary
In this blog post we derived the principles of physically based rendering from scratch, and implemented a differentiable path tracer in pure JAX. There are three kinds of radiometric integrals (solid angle, projected solid angle, and area) that come up in a basic implementations of a path tracer and we used all three to implement a path tracer that separates direct lighting contributions from area lights separately from indirect lighting bouncing from non-light surfaces.
JAX provides us with a lot of useful features to implement this:
- You can write a one-pixel path tracer and vmap it into a vectorized version without sacrificing performance. You can parallelize trivially across devices using pmap.
- Code runs on GPU and TPU without modifications.
- Analytical surface normals of signed distance fields provided by automatic differentiation.
- Lightweight enough to run in a Jupyter/Colaboratory notebook, making it ideal for trying out graphics research ideas without getting bogged down by software engineering abstractions.
There are still some sharp bits with JAX because graphics and rendering workloads are not its first-class customers. Still, I think there is a lot of promise and future work to be done with combining the programmatic expressivity of modern deep learning frameworks with the field of graphics.
We didn't explore the differentiability of this path tracer, but rest assured that the combination of ray-marching and Monte Carlo path integration makes everything tractable. Stay tuned for the next part of the tutorial, when we mix differentiation of this path tracer with neural networks and machine learning.
Acknowledgements
Thanks to Luke Metz, Jonathan Tompson, Matt Pharr for interesting discussion a few years ago when I wrote the first version of this code in TensorFlow. Many thanks to Peter Hawkins, James Bradbury, and Stephan Hoyer for teaching me more about JAX and XLA. Thanks to Yining Karl Li for entertaining my dumb rendering questions and Vincent Vanhoucke for catching typos.
Fun Facts
- Jim Kajiya's first path tracer took 7 hours to render a 256x256 image on a 280,000 USD IBM computer. By comparison, this renderer takes about 10 seconds to render an image of similar size, and you can run it for free with Google's free hosted colab notebooks that come with JAX pre-installed.
- I didn't discuss photometry much in this tutorial, but it turns out that the SI unit of photometric density, the candela, is the only SI base unit related to a biological process (human vision system).
- Check out my blog post on normalizing flows for more info on how "conservation of probability mass'' is employed in deep learning research!
- OpenDR was one of the first general-purpose differentiable renderers, and was technically innovative enough to merit publishing in ECCV 2014. It's remarkable to see how easy writing a differentiable renderer has become with modern deep learning frameworks like JAX, Pytorch, and TensorFlow.
Wednesday, November 6, 2019
Robinhood, Leverage, and Lemonade
DISCLAIMER: NO INVESTMENT OR LEGAL ADVICE
The Content is for informational purposes only, you should not construe any such information or other material as legal, tax, investment, financial, or other advice. Investing involves risk, please consult a financial professional before making an investment.
The Content is for informational purposes only, you should not construe any such information or other material as legal, tax, investment, financial, or other advice. Investing involves risk, please consult a financial professional before making an investment.
Robinhood is a zero-commission brokerage that was founded in 2013. It has a beautiful mobile user interface that game-ifies the gambling of your life savi—, er, makes it seamless for millennials to buy and sell stocks.
I wrote on Quora in Dec 2014 on why lowering the barrier to entry to this extent can cause retail investors to make trades without knowing what they are doing. That post turned out to be rather prescient, for reasons I’ll explain below.
One of the ways Robinhood makes money is via margin lending: they loan you some extra money to invest in the stock market with, and later you pay back the loan with some interest (currently about 5%).
If you are in the business of lending money, not only do you have to safeguard your brokerage system against technological vulnerabilities (e.g. C++ memory leaks that expose users’ trades), but you also need to defend against financial vulnerabilities, which are portfolios that expose the lender or its customers to an irresponsible amount of investment risk.
In the last few months it has come to light [1, 2, 3, 4, 5] that there are some serious financial vulnerabilities in Robinhood’s margin lending platform, whereby it is possible for users to borrow much, much more money from Robinhood than they are supposed to.
These users subsequently gamble huge amounts of borrowed money away in a coin toss, leaving Robinhood in a very bad spot, perhaps even at odds with Regulation T laws (I am not a lawyer, just speculating here).
“Leverage” is one of the most important concepts to understand in finance, and when used judiciously, is a net positive for everyone involved. It is important for everyone to understand how credit works, and how much leverage is too much. Borrowing more money than you can afford to pay back can take many forms, whether it is taking on college debt, credit card debt, or raising VC money.
Here’s a tutorial on “financial leverage” in the form of a story about lemonade:
It’s a hot summer, and you decide to start a lemonade stand to make some money. You have 100€, with which you can buy enough ingredients to make 120€ of lemonade for the summer. Your “return on investment”, or ROI, for the summer is 20%, since you ended up with 20% more money than you started with.
You also figure that if you had another 200€, enough people want lemonade that you could sell three times as much lemonade and make 360€. But you don’t have 200€ to spare! What do you do?
You could use the 120€ to build a slightly bigger lemonade operation next year. Assuming you could get a 20% ROI again next summer, you end up with 144€. But it will be many years before you even have 300€! By this time next year, lemonade might be out of fashion and kids might be juuling at home watching Netflix instead. You would much prefer to scale up your lemonade operation now, while you are confident that you can sell lemonade at a "profit margin" of 20%.
Fortunately, your friend “Britney Banker” is very wealthy and can lend you 200€. Britney Banker doesn’t have your entrepreneurial spirit, so she lacks the ability to get a 20% ROI on her own money. She offers to give you 200€ today, in exchange for you giving her 210€ at the end of the year -- an interest rate of 5%. Your “capital leverage ratio” is 100 / 200 = 1:2, because for every dollar you own, Britney is willing to lend you 2€.
If things turn out well, you sell 360€ worth of lemonade, pay Britney back 210€, and pocket the remaining 150€. Starting with 100€, you were able to use borrowed money to “magnify” your return to 50%.
However, if you make 200€ worth of lemonade and fail to sell any of it before the lemonade spoils and became worthless, you would be in a very sticky situation! You would have worthless lemonade and a 210€ debt to Britney. This is far worse than if you had lost your own 100€, because at least you wouldn’t owe anyone anything afterwards. So even though 1:2 leverage may amplify your gains from 20% → 50%, so it may amplify your potential losses from 100% → -310%!
The only reason why Britney is willing to lend you the money in the first place is that Britney thinks this outcome (you losing all of the borrowed money on top of your own assets) is unlikely. If Britney thought that you were less reliable, she might offer you a smaller leverage ratio (e.g. 1 : 1.5).
Suppose you make a big batch of lemonade (with Britney’s money) and then go door to door selling lemonade, but instead of giving customers a delicious drink right away, you give them a “deep-in-the-lemonade covered call option”. You take their money up front, and give them a coupon that allows them to “buy” a lemonade for free (0€).
The "call option" is referred to as "covered" because you actually have the lemonade to go with the coupon, it's just that you're holding onto the lemonade until the buyer actually redeems the coupon.

You then go back to Britney and say “I have 360€ of lemonade that I’ve made but haven’t sold, and 360€ in cash from selling lemonade options to customers, and as for debts there’s 200€ I’ve borrowed from you. That’s 520€ in net assets, so can I please borrow 1040€?”.
Britney says “sure, that’s a 1:2 leverage ratio”, and writes you a check for 1040€, again with 5% interest. But Britney has made a tragic mistake here! The 360€ in lemonade she counted as your assets are not really yours to spend, because you actually owe them in obligations to customers.
With 1204€ in borrowed assets, you are now leveraged over 1:12 !
You repeat this process again, turning 1040€ cash into 1248€ of lemonade, selling an additional 1248€ of deep-in-the-lemonade options. You now have 1608€ of lemonade, and 1608€ in cash, and 1204€ of debt, for net assets of 1608 + 1608 - 1204 = 2012€.
You go back to Britney and ask to borrow another 4024€, with 5% interest. Again, because Britney is forgetting to account for the 1608€ in lemonade “debt” that you may have to deliver to coupon-holders, she thinks that the leverage is still 1:2. You repeat this process one more time, and your new total position is 6k€ in lemonade, 6k€ in cash, 5k€ net debt.
If you were to successfully deliver 6k€ of lemonade, you would make 1k€ in profit, starting from only 100€ of your own cash. A 1000% return sounds too good to be true, right? That’s because it is.
One hot summer day, all of the coupon holders decide to exercise their coupons at the same time. You realize that your lemonade stand can’t actually fulfill 6k€ in lemonade orders and you are in way over your head. Desperate, you attempt to pivot and come up with a Billy Mcfarland-esque scheme to buy lemonade from a local grocery and dilute it with some water. But due to inexperience with food handling operations, you accidentally contaminate half the batch, and are left with only 3k€ of lemonade. You have 6k€ cash but still owe 3k€ in lemonade and 5k€ in cash.Your 1k€ profit opportunity has now become a 2k€ DEBT (ROI of -2100%), and we haven't even factored in the interest! Because the debtors (lemonade coupon holders and Britney Banker) must be paid regardless of whether you successfully make lemonade or not, your leverage has an asymmetric payoff - the downsides are twice as bad as the upside!
I wish I could say that this story was fictional, but to the best of my understanding this is more or less what /u/ControlTheNarrative and others attempted to do on Robinhood. Substitute "lemonade" for "AMD stock", and "lemonade coupon" for "deep-in-the-money covered call option". Theoretically, Robinhood shouldn't allow you to buy options on margin, but /u/ControlTheNarrative was very clever to use covered call options, which meant that he bought AMD stock with margin (valid) and then created cash and in-the-money AMD call options (sort of like creating matter and antimatter from nothing). Robinhood failed to detect the "antimatter", allowing /u/ControlTheNarrative to mask his "debt", thereby doubling his apparent net assets.
Ok, where did /u/ControlTheNarrative go wrong? It might be possible to still turn a profit by investing the vast amount of leverage in a “safe asset”, right? This seems unlikely: Robinhood’s interest rate of 5% far exceeds the risk-free rate of 1.88% currently offered by a 1-year Treasury note. In other words, it only makes sense to use Robinhood's leverage when you have the ability to deliver annualized returns that exceed 5%. When one has limited assets and a risky investment opportunity, they should instead carefully choose leverage so that they do not end up owing 10x their net worth should they encounter a stroke of bad luck.
Instead of trying to find an investment that minimizes risk while maintaining >5% return, /u/ControlTheNarrative proceeded to then take his enormous leverage and bet all of that on a coin toss: out-of-the-money (OTM) put options against Apple (remember that he is able to buy these options with leveraged cash because it has been "laundered" using covered call options).
Unfortunately for him, Apple proceeded to beat performance expectations for earnings, and subsequently the OTM options became worthless!
Guh!
Thanks to Ted Xiao and Daniel Ho for insightful discussion. We had a good laugh. I found the following links helpful in my research:
I wrote on Quora in Dec 2014 on why lowering the barrier to entry to this extent can cause retail investors to make trades without knowing what they are doing. That post turned out to be rather prescient, for reasons I’ll explain below.
One of the ways Robinhood makes money is via margin lending: they loan you some extra money to invest in the stock market with, and later you pay back the loan with some interest (currently about 5%).
If you are in the business of lending money, not only do you have to safeguard your brokerage system against technological vulnerabilities (e.g. C++ memory leaks that expose users’ trades), but you also need to defend against financial vulnerabilities, which are portfolios that expose the lender or its customers to an irresponsible amount of investment risk.
In the last few months it has come to light [1, 2, 3, 4, 5] that there are some serious financial vulnerabilities in Robinhood’s margin lending platform, whereby it is possible for users to borrow much, much more money from Robinhood than they are supposed to.
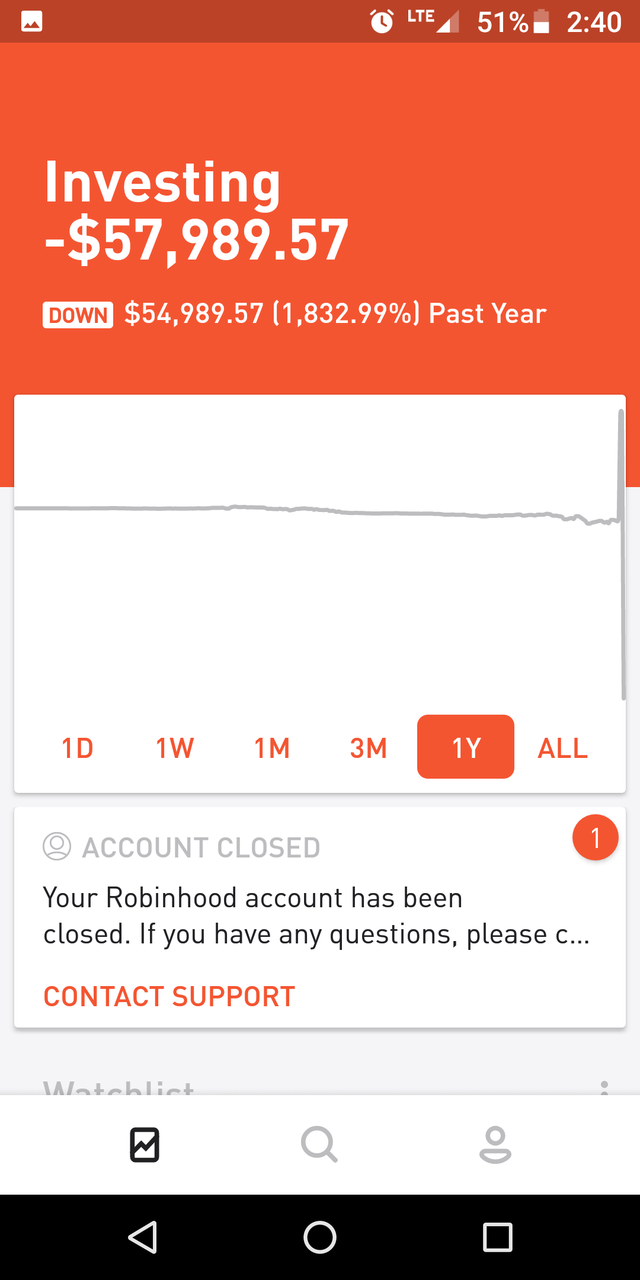
These users subsequently gamble huge amounts of borrowed money away in a coin toss, leaving Robinhood in a very bad spot, perhaps even at odds with Regulation T laws (I am not a lawyer, just speculating here).
“Leverage” is one of the most important concepts to understand in finance, and when used judiciously, is a net positive for everyone involved. It is important for everyone to understand how credit works, and how much leverage is too much. Borrowing more money than you can afford to pay back can take many forms, whether it is taking on college debt, credit card debt, or raising VC money.
Here’s a tutorial on “financial leverage” in the form of a story about lemonade:
Lemonade Leverage
It’s a hot summer, and you decide to start a lemonade stand to make some money. You have 100€, with which you can buy enough ingredients to make 120€ of lemonade for the summer. Your “return on investment”, or ROI, for the summer is 20%, since you ended up with 20% more money than you started with.
You also figure that if you had another 200€, enough people want lemonade that you could sell three times as much lemonade and make 360€. But you don’t have 200€ to spare! What do you do?
You could use the 120€ to build a slightly bigger lemonade operation next year. Assuming you could get a 20% ROI again next summer, you end up with 144€. But it will be many years before you even have 300€! By this time next year, lemonade might be out of fashion and kids might be juuling at home watching Netflix instead. You would much prefer to scale up your lemonade operation now, while you are confident that you can sell lemonade at a "profit margin" of 20%.
Fortunately, your friend “Britney Banker” is very wealthy and can lend you 200€. Britney Banker doesn’t have your entrepreneurial spirit, so she lacks the ability to get a 20% ROI on her own money. She offers to give you 200€ today, in exchange for you giving her 210€ at the end of the year -- an interest rate of 5%. Your “capital leverage ratio” is 100 / 200 = 1:2, because for every dollar you own, Britney is willing to lend you 2€.
If things turn out well, you sell 360€ worth of lemonade, pay Britney back 210€, and pocket the remaining 150€. Starting with 100€, you were able to use borrowed money to “magnify” your return to 50%.
However, if you make 200€ worth of lemonade and fail to sell any of it before the lemonade spoils and became worthless, you would be in a very sticky situation! You would have worthless lemonade and a 210€ debt to Britney. This is far worse than if you had lost your own 100€, because at least you wouldn’t owe anyone anything afterwards. So even though 1:2 leverage may amplify your gains from 20% → 50%, so it may amplify your potential losses from 100% → -310%!
The only reason why Britney is willing to lend you the money in the first place is that Britney thinks this outcome (you losing all of the borrowed money on top of your own assets) is unlikely. If Britney thought that you were less reliable, she might offer you a smaller leverage ratio (e.g. 1 : 1.5).
Lemonade Coupons
Suppose you make a big batch of lemonade (with Britney’s money) and then go door to door selling lemonade, but instead of giving customers a delicious drink right away, you give them a “deep-in-the-lemonade covered call option”. You take their money up front, and give them a coupon that allows them to “buy” a lemonade for free (0€).
The "call option" is referred to as "covered" because you actually have the lemonade to go with the coupon, it's just that you're holding onto the lemonade until the buyer actually redeems the coupon.

You then go back to Britney and say “I have 360€ of lemonade that I’ve made but haven’t sold, and 360€ in cash from selling lemonade options to customers, and as for debts there’s 200€ I’ve borrowed from you. That’s 520€ in net assets, so can I please borrow 1040€?”.
Britney says “sure, that’s a 1:2 leverage ratio”, and writes you a check for 1040€, again with 5% interest. But Britney has made a tragic mistake here! The 360€ in lemonade she counted as your assets are not really yours to spend, because you actually owe them in obligations to customers.
With 1204€ in borrowed assets, you are now leveraged over 1:12 !
You repeat this process again, turning 1040€ cash into 1248€ of lemonade, selling an additional 1248€ of deep-in-the-lemonade options. You now have 1608€ of lemonade, and 1608€ in cash, and 1204€ of debt, for net assets of 1608 + 1608 - 1204 = 2012€.
You go back to Britney and ask to borrow another 4024€, with 5% interest. Again, because Britney is forgetting to account for the 1608€ in lemonade “debt” that you may have to deliver to coupon-holders, she thinks that the leverage is still 1:2. You repeat this process one more time, and your new total position is 6k€ in lemonade, 6k€ in cash, 5k€ net debt.
If you were to successfully deliver 6k€ of lemonade, you would make 1k€ in profit, starting from only 100€ of your own cash. A 1000% return sounds too good to be true, right? That’s because it is.
One hot summer day, all of the coupon holders decide to exercise their coupons at the same time. You realize that your lemonade stand can’t actually fulfill 6k€ in lemonade orders and you are in way over your head. Desperate, you attempt to pivot and come up with a Billy Mcfarland-esque scheme to buy lemonade from a local grocery and dilute it with some water. But due to inexperience with food handling operations, you accidentally contaminate half the batch, and are left with only 3k€ of lemonade. You have 6k€ cash but still owe 3k€ in lemonade and 5k€ in cash.Your 1k€ profit opportunity has now become a 2k€ DEBT (ROI of -2100%), and we haven't even factored in the interest! Because the debtors (lemonade coupon holders and Britney Banker) must be paid regardless of whether you successfully make lemonade or not, your leverage has an asymmetric payoff - the downsides are twice as bad as the upside!
I wish I could say that this story was fictional, but to the best of my understanding this is more or less what /u/ControlTheNarrative and others attempted to do on Robinhood. Substitute "lemonade" for "AMD stock", and "lemonade coupon" for "deep-in-the-money covered call option". Theoretically, Robinhood shouldn't allow you to buy options on margin, but /u/ControlTheNarrative was very clever to use covered call options, which meant that he bought AMD stock with margin (valid) and then created cash and in-the-money AMD call options (sort of like creating matter and antimatter from nothing). Robinhood failed to detect the "antimatter", allowing /u/ControlTheNarrative to mask his "debt", thereby doubling his apparent net assets.
Ok, where did /u/ControlTheNarrative go wrong? It might be possible to still turn a profit by investing the vast amount of leverage in a “safe asset”, right? This seems unlikely: Robinhood’s interest rate of 5% far exceeds the risk-free rate of 1.88% currently offered by a 1-year Treasury note. In other words, it only makes sense to use Robinhood's leverage when you have the ability to deliver annualized returns that exceed 5%. When one has limited assets and a risky investment opportunity, they should instead carefully choose leverage so that they do not end up owing 10x their net worth should they encounter a stroke of bad luck.
Instead of trying to find an investment that minimizes risk while maintaining >5% return, /u/ControlTheNarrative proceeded to then take his enormous leverage and bet all of that on a coin toss: out-of-the-money (OTM) put options against Apple (remember that he is able to buy these options with leveraged cash because it has been "laundered" using covered call options).
Unfortunately for him, Apple proceeded to beat performance expectations for earnings, and subsequently the OTM options became worthless!
Guh!
Acknowledgements
Thanks to Ted Xiao and Daniel Ho for insightful discussion. We had a good laugh. I found the following links helpful in my research:
- https://www.reddit.com/r/wallstreetbets/comments/dqg6xx/infinite_leverage_explained/
- https://www.bloomberg.com/opinion/articles/2019-11-05/playing-the-game-of-infinite-leverage
Subscribe to:
Posts (Atom)