In a previous blog post, I also discussed how iterating in simulation solves some tricky problems around new code changes invalidating old data. Simulation makes this a non-issue because it is relatively cheap to re-generate your dataset every time you change the code.
Despite significant sim2real advances in the last decade, I must confess that three years ago, I was still somewhat ideologically opposed to doing robotics research in simulation, on the grounds that we should revel in the richness and complexity of real data, as opposed to perpetually staying in the safe waters of simulation.
Following those beliefs, I worked on a three-year long robotics project where our team eschewed simulation and focused the majority of our time on iterating in the real world (mea culpa). That project was a success, and the paper will be presented at the 2021 Conference on Robotic Learning. However, in the process, I learned some hard lessons that completely reversed my stance on sim2real and offline policy evaluation. I now believe that offline evaluation technology is no longer optional if you are studying general-purpose robots, and I have pivoted my research workflows to rely much more heavily on these methods. In this blog post, I outline why it is tempting for roboticists to iterate directly on real life, and how the difficulty of evaluating general-purpose robots will eventually force us to increasingly rely on offline evaluation techniques such as simulation.
Two Flavors of Sim2Real
I’m going to assume the reader is familiar with basic sim2real techniques. If not, please check out this RSS’2020 workshop website for tutorial videos. There are broadly two ways to formalize sim2real problems.
One approach is to create an “adapter” that transforms simulated sensor readings to resemble real data as much as possible, so that a robot trained in simulation behaves indistinguishably in both simulation and real. Progress on generative modeling techniques such as GANs have enabled this to work even for natural images.
Another formulation of the sim2real problem is to train simulated robots under lots of randomized conditions. In becoming robust under varied conditions, the simulated policy can treat the real world as just another instance under the training distribution. OpenAI’s Dactyl took this “domain randomization” approach, and were able to get the robot to manipulate a Rubik’s cube without ever doing policy learning on real data.
Both the domain adaptation and domain randomization approaches in practice yield similar results when transferred to real, so their technical differences are not super important. The takeaway is that the policy is learned and evaluated on simulated data, then deployed in real with fingers crossed.
The Case For Iterating Directly In Real
- Reality is messy and complicated. It takes regular upkeep and effort to maintain neatness for a desk or bedroom or apartment. Meanwhile, robot simulations tend to be neat and sterile by default, with not a lot of “messiness” going on. In simulation, you must put in extra work to increase disorder, whereas in the real world, entropy increases for free. This acts as a forcing function for roboticists to focus on the scalable methods that can handle the complexity of the real world.
- Some things are inherently difficult to simulate - in the real world, you can have robots interact with all manner of squishy toys and articulated objects and tools. Bringing those objects into a simulation is incredibly difficult. Even if one uses photogrammetry technology to scan objects, one still needs to set-dress objects in the scene to make a virtual world resemble a real one. Meanwhile, in the real world one can collect rich and diverse data by simply grabbing the nearest household object - no coding required.
- Bridging the “reality gap” is a hard research problem (often requiring training high-dimensional generative models), and it’s hard to know whether these models are helping until one is running actual robot policies in the real world anyway. It felt more pragmatic to focus on direct policy learning on the test setting, where one does not have to wonder whether their training distribution differs from their test distribution.
To put those beliefs into context, at the time, I had just finished working on Grasp2Vec and Time-Contrastive-Networks, both of which leveraged rich real-world data to learn interesting representations. The neat thing about these papers was that we could train these models on whatever object (Grasp2Vec) or video demonstration (TCN) the researcher felt like mixing into the training data, and scale up the system without writing a single line of code. For instance, if you want to gather a teleoperated demonstration of a robot playing with a Rubik’s cube, you simply need to buy a Rubik’s cube from a store and put it into the robot workspace. In simulation, you would have to model a simulated equivalent of a rubik’s cube that twists and turns just like a real one - this can be a multi-week effort just to align the physical dynamics correctly. It didn’t hurt that the models “just worked”, there wasn’t much iteration needed on the modeling front for us to start seeing cool generalization.
There were two more frivolous reasons I didn’t like sim2real:
Aesthetics: Methods that learn in simulation often rely on crutches that are only possible in simulation, not real. For example, using millions of trials with an online policy-gradient method (PPO, TRPO) or the ability to reset the simulation over and over again. As someone who is inspired by the sample efficiency of humans and animals, and who believes in the LeCake narrative of using unsupervised learning algorithms on rich data, relying on a “simulation crutch” to learn feels too ham-handed. A human doesn’t need to suffer a fatal accident to learn how to drive a car.
A “no-true-Scotsman” bias: I think there is a tendency for people who spend all their time iterating in simulation to forget the operational complexity of the real world. Truthfully, I may have just been envious of others who were publishing 3-4 papers a year on new ideas in simulated domains, while I was spending time answering questions like “why is the gripper closing so slowly?”
So how did I change my mind? Many researchers at the intersection of ML and Robotics are working towards the holy grail of “generalist robots that can do anything humans ask them”. Once you have the beginnings of such a system, you start to notice a host of new research problems you didn’t think of before, and this is how I came to realize that I was wrong about simulation.
In particular, there is a “Problem of Success”: how do we go about improving such generalist robots? If the success rate is middling, say, 50%, how do we accurately evaluate a system that can generalize to thousands or millions of operating conditions? The feeling of elation that a real robot has learned to do hundreds of things -- perhaps even things that people didn’t train them for -- is quickly overshadowed by uncertainty and dread of what to try next.
Let’s consider, for example, a generalist cooking robot - perhaps a bipedal humanoid that one might deploy in any home kitchen to cook any dish, including Wozniak’s Coffee Test (A machine is required to enter an average American home and figure out how to make coffee: find the coffee machine, find the coffee, add water, find a mug, and brew the coffee by pushing the proper buttons).
In research, a common metric we’d like to know is the average success rate - what is the overall success rate of the robot at performing a number of different tasks around the kitchen?
In order to estimate this quantity, we must average over the set of all things the robot is supposed to generalize to, by sampling different tasks, different starting configurations of objects, different environments, different lighting conditions, and so on.
A “no-true-Scotsman” bias: I think there is a tendency for people who spend all their time iterating in simulation to forget the operational complexity of the real world. Truthfully, I may have just been envious of others who were publishing 3-4 papers a year on new ideas in simulated domains, while I was spending time answering questions like “why is the gripper closing so slowly?”
Suffering From Success: Evaluating General Purpose Robots
So how did I change my mind? Many researchers at the intersection of ML and Robotics are working towards the holy grail of “generalist robots that can do anything humans ask them”. Once you have the beginnings of such a system, you start to notice a host of new research problems you didn’t think of before, and this is how I came to realize that I was wrong about simulation.
In particular, there is a “Problem of Success”: how do we go about improving such generalist robots? If the success rate is middling, say, 50%, how do we accurately evaluate a system that can generalize to thousands or millions of operating conditions? The feeling of elation that a real robot has learned to do hundreds of things -- perhaps even things that people didn’t train them for -- is quickly overshadowed by uncertainty and dread of what to try next.
Let’s consider, for example, a generalist cooking robot - perhaps a bipedal humanoid that one might deploy in any home kitchen to cook any dish, including Wozniak’s Coffee Test (A machine is required to enter an average American home and figure out how to make coffee: find the coffee machine, find the coffee, add water, find a mug, and brew the coffee by pushing the proper buttons).
In research, a common metric we’d like to know is the average success rate - what is the overall success rate of the robot at performing a number of different tasks around the kitchen?
In order to estimate this quantity, we must average over the set of all things the robot is supposed to generalize to, by sampling different tasks, different starting configurations of objects, different environments, different lighting conditions, and so on.

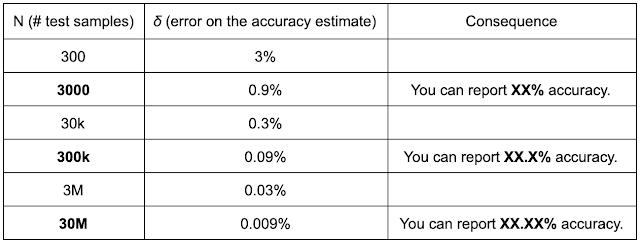
For a single scenario, it takes a substantial number of trials to measure success rates with single digit precision:
The standard deviation of a binomial parameter is given by sqrt(P*(1-P)/N), where P is the sample mean and N is the sample size. If your empirical mean of the success rate is 50% under N=5000 samples, this equation tells you that the standard error is 0.007. A more intuitive way to understand this is in terms of a confidence interval: there is a 95% epistemic probability that the true mean, which may not be exactly 50%, lies within the range [50 - 1.3, 50 + 1.3].
5000 trials is a lot of work! Rarely do real robotics experiments do anywhere near 300 or even 3000 evaluations to measure task success.
From Vincent Vanhoucke’s blog post, here is a table drawing a connection from your sample size (under the worst case of p=50%, which maximizes standard error) to the number of significant digits you can report:
Depending on the length of the task, it could take all day or all week or all month to run one experiment. Furthermore, until robots are sufficiently capable of resetting their own workspaces, a human supervisor needs to reset the workspace over and over again as one goes through the evaluation tasks.
One consequence of these napkin calculations is that pushing the frontier of robotic capability requires a series of incremental advances (e.g. 1% at a time) with extremely costly evaluation (5000 episodes per iteration), or a series of truly quantum advances that are so large in magnitude that it takes very few samples to know that the result is significant. Going from “not working at all” to “kind of working” is one example of a large statistical leap, but in general it is hard to pull these out of the hat over and over again.
Techniques like A/B testing can help reduce the variance of estimating whether one model is better than another one, but it still does not address the problem of the sample complexity of evaluation growing exponentially with the diversity of conditions the ML models are expected to generalize to.
What about a high-variance, unbiased estimator? One approach would be to sample a location at random, then a task at random, and then an initial scene configuration at random, and then aggregate thousands of such trials into a single “overall success estimator”. This is tricky to work with because it does not help the researcher drill into problems where learning under one set of conditions causes catastrophic forgetting of another number. Furthermore, if the number of training tasks is many times larger than the number of evaluation samples and task successes are not independent, then there will be high variance in the overall success estimate.
What about evaluating general robots with a biased, low-variance estimator of the overall task success? We could train a cooking robot to make millions of dishes, but only evaluate on a few specific conditions - for example, measuring the robot’s ability to make banana bread and using that as an estimator for its ability to do all the other tasks. Catastrophic forgetting is still a problem - if the success rate of making banana bread is inversely correlated with the success rate of making stir-fry, then you may be crippling the robot in ways that you are no longer measuring. Even if that isn’t a problem, having to collect 5000 trials limits the number of experiments one can evaluate on any given day. Also, you end up with a lot of surplus banana bread.
The following is a piece of career advice, rather than a scientific claim: in general you should strive to be in a position where your productivity bottleneck is the number of ideas you can come up with in a single day, rather than some physical constraint that limits you to one experiment per day. This is true in any scientific field, whether it be in biology or robotics.
Lesson: Scaling up in reality is fast because it requires little to no additional coding, but once you have a partially working system, careful empirical evaluation in real life becomes increasingly difficult as you increase the generality of the system.
In his 2011 essay Software is Eating The World, venture capitalist Marc Andreessen pointed out that more and more of the value chain in every sector of the world was being captured by software companies. In the ensuing decade, Andreesen has refined his idea further to point out that “Software Eating The World” is a continuation of a technological trend, Ephemeralization, that precedes even the computer age. From Wikipedia:
Ephemeralization, a term coined by R. Buckminster Fuller in 1938, is the ability of technological advancement to do "more and more with less and less until eventually you can do everything with nothing,"
Consistent with this theme, I believe the solution to scaling up generalist robotics is to push as much of the iteration loop into software as possible, so that the researcher is freed from the sheer slowness of having to iterate in the real world.
Andreessen has posed the question of how future markets and industries might change when everybody has access to such massive leverage via “infinite compute”. ML researchers know that “infinite” is a generous approximation - it still costs 12M USD to train a GPT-3 level language model. However, Andreessen is directionally correct - we should dare to imagine a near future where compute power is practically limitless to the average person, and let our careers ride this tailwind of massive compute expansion. Compute and informational leverage are probably still the fastest growing resources in the world.
Software is also eating research. I used to work in a biology lab at UCSF, where only a fraction of postdoc time was spent thinking about the science and designing experiments. The majority of time was spent pipetting liquids into PCR plates, making gel media, inoculating petri dishes, and generally moving liquids around between test tubes. Today, it is possible to run a number of “standard biology protocols” in the cloud, and one could conceivably spend most of their time focusing on the high-brow experiment design and analysis rather than manual labor.

Imagine a near future where instead of doing experiments on real mice, we instead simulate a highly accurate mouse behavioral model. If such models turn out to be accurate, then medical science will be revolutionized overnight by virtue of researchers being able to launch massive-scale studies with billions of simulated mouse models. A single lab might be able to replicate a hundred years of mouse behavioral studies practically overnight. A scientist working on a laptop from a coffee shop might be able to design a drug, run clinical trials on it using a variety of cloud services, and get it FDA approved all from her laptop. When this happens, Fuller’s prediction will come true and it really will seem as if we can do “everything with nothing”.
The most obvious way to ephemeralize robot learning in software is to make simulations that resemble reality as closely as possible. Simulators are not perfect - they still suffer from the reality gap and data richness problems that originally made me skeptical of iterating in simulation. But, having worked on general purpose robots directly in the real world, I now believe that people who want high-growth careers should actively seek workflows with highest leverage, even if it means putting in the legwork to make a simulation as close to reality as possible.
There may be ways to ephemeralize robotic evaluation without having to painstakingly hand-design Rubik’s cubes and human behavior into your physics engine. One solution is to use machine learning to learn world models from data, and having the policy interact with the world model instead of the real world for evaluation. If learning high-dimensional generative models is too hard, there are off-policy evaluation methods and offline hyperparameter selection methods that don’t necessarily require simulation infrastructure. The basic intuition is that if you have a value function for a good policy, you can use it to score other policies on your real world validation datasets. The downside to these methods is that they often require finding good policy or value function to begin with, and are only accurate for ranking policies up to the level of the aforementioned policy itself. A Q(s,a) function for a policy with a 70% success rate can tell you if your new model is performing around 70% or 30% , but is not effective at telling you whether you will get 95% (since these models don’t know what they don’t know). Some preliminary research suggests that extrapolation can be possible, but it has not yet been demonstrated at the scale of evaluating general-purpose robots on millions of different conditions.
What are some alternatives to more realistic simulators? Much like the “lab in the cloud” business, there are some emerging cloud-hosted benchmarks such as AI2Thor and MPI’s Real Robot Challenge, where researchers can simply upload their code and get back results. The robot cloud provider handles all of the operational aspects of physical robots, freeing the researcher to focus on software.

One drawback of these setups is that these hosted platforms are designed for repeatable, resettable experiments, and do not have the diversity that general purpose robots would be exposed to.
Alternatively, one could follow the Tesla Autopilot approach and deploy their research code in “shadow mode” across a fleet of robots in the real world, where the model only makes predictions but does not make control decisions. This exposes evaluation to high-diversity data that cloud benchmarks don’t have, but suffers from the long-term credit assignment problem. How do we know whether a predicted action is good or not if the agent isn’t allowed to take those actions?
For these reasons, I think data-driven realistic simulation gets the best of both worlds - you get the benefits of real world diverse data and the ability to evaluate simulated long-term outcomes. Even if you are relying heavily on real-world evaluations via a hosted cloud robotics lab or a fleet running Shadow Mode, having a complementary software-only evaluation provides additional signal can only help with saving costs and time.
I suspect that a practical middle ground is to combine multiple signals from offline metrics to predict success rate: leveraging simulation to measure success rates, training world models or value functions to help predict what will happen in “imagined rollouts”, adapting simulation images to real-like data with GANs, and using old-fashioned data science techniques (logistic regression) to study the correlations between these offline metrics and real evaluated success. As we build more general AI systems that interact with the real world, I predict that there will be cottage industries dedicated to building simulators dedicated for sim2real evaluation and data scientists who build bespoke models for guessing the result of expensive real-world evaluations.
Separately from how ephemeralization drives down the cost of evaluating robots in the real world, there is the effect of ephemeralization driving down the cost of robot hardware itself. It used to be that robotics labs could only afford a couple expensive robot arms from Kuka and Franka. Each robot would cost hundreds of thousands of dollars, because they had precisely engineered encoders and motors that enabled millimeter-level precision. Nowadays, you can buy some cheap servos from AliExpress.com for a few hundred dollars, glue it to some metal plates, and control it in a closed-loop manner using a webcam and a neural network running on a laptop.
Instead of relying on hardware precise position control, the arm moves based purely on vision and hand-eye coordination. All the complexity has been migrated from hardware to software (and machine learning). This technology is not mature enough yet for factories and automotive companies to replace their precision machines with cheap servos, but the writing is on the wall: software is coming for hardware, and this trend will only accelerate.
- http://www.nowozin.net/sebastian/blog/how-to-report-uncertainty.html
- https://towardsdatascience.com/digit-significance-in-machine-learning-dea05dd6b85b
- https://stats.stackexchange.com/questions/322953/number-of-significant-figures-to-report-for-a-confidence-interval
The standard deviation of a binomial parameter is given by sqrt(P*(1-P)/N), where P is the sample mean and N is the sample size. If your empirical mean of the success rate is 50% under N=5000 samples, this equation tells you that the standard error is 0.007. A more intuitive way to understand this is in terms of a confidence interval: there is a 95% epistemic probability that the true mean, which may not be exactly 50%, lies within the range [50 - 1.3, 50 + 1.3].
5000 trials is a lot of work! Rarely do real robotics experiments do anywhere near 300 or even 3000 evaluations to measure task success.
From Vincent Vanhoucke’s blog post, here is a table drawing a connection from your sample size (under the worst case of p=50%, which maximizes standard error) to the number of significant digits you can report:
Depending on the length of the task, it could take all day or all week or all month to run one experiment. Furthermore, until robots are sufficiently capable of resetting their own workspaces, a human supervisor needs to reset the workspace over and over again as one goes through the evaluation tasks.
One consequence of these napkin calculations is that pushing the frontier of robotic capability requires a series of incremental advances (e.g. 1% at a time) with extremely costly evaluation (5000 episodes per iteration), or a series of truly quantum advances that are so large in magnitude that it takes very few samples to know that the result is significant. Going from “not working at all” to “kind of working” is one example of a large statistical leap, but in general it is hard to pull these out of the hat over and over again.
Techniques like A/B testing can help reduce the variance of estimating whether one model is better than another one, but it still does not address the problem of the sample complexity of evaluation growing exponentially with the diversity of conditions the ML models are expected to generalize to.
What about a high-variance, unbiased estimator? One approach would be to sample a location at random, then a task at random, and then an initial scene configuration at random, and then aggregate thousands of such trials into a single “overall success estimator”. This is tricky to work with because it does not help the researcher drill into problems where learning under one set of conditions causes catastrophic forgetting of another number. Furthermore, if the number of training tasks is many times larger than the number of evaluation samples and task successes are not independent, then there will be high variance in the overall success estimate.
What about evaluating general robots with a biased, low-variance estimator of the overall task success? We could train a cooking robot to make millions of dishes, but only evaluate on a few specific conditions - for example, measuring the robot’s ability to make banana bread and using that as an estimator for its ability to do all the other tasks. Catastrophic forgetting is still a problem - if the success rate of making banana bread is inversely correlated with the success rate of making stir-fry, then you may be crippling the robot in ways that you are no longer measuring. Even if that isn’t a problem, having to collect 5000 trials limits the number of experiments one can evaluate on any given day. Also, you end up with a lot of surplus banana bread.
The following is a piece of career advice, rather than a scientific claim: in general you should strive to be in a position where your productivity bottleneck is the number of ideas you can come up with in a single day, rather than some physical constraint that limits you to one experiment per day. This is true in any scientific field, whether it be in biology or robotics.
Lesson: Scaling up in reality is fast because it requires little to no additional coding, but once you have a partially working system, careful empirical evaluation in real life becomes increasingly difficult as you increase the generality of the system.
Ephemeralization
Ephemeralization, a term coined by R. Buckminster Fuller in 1938, is the ability of technological advancement to do "more and more with less and less until eventually you can do everything with nothing,"
Consistent with this theme, I believe the solution to scaling up generalist robotics is to push as much of the iteration loop into software as possible, so that the researcher is freed from the sheer slowness of having to iterate in the real world.
Andreessen has posed the question of how future markets and industries might change when everybody has access to such massive leverage via “infinite compute”. ML researchers know that “infinite” is a generous approximation - it still costs 12M USD to train a GPT-3 level language model. However, Andreessen is directionally correct - we should dare to imagine a near future where compute power is practically limitless to the average person, and let our careers ride this tailwind of massive compute expansion. Compute and informational leverage are probably still the fastest growing resources in the world.
Software is also eating research. I used to work in a biology lab at UCSF, where only a fraction of postdoc time was spent thinking about the science and designing experiments. The majority of time was spent pipetting liquids into PCR plates, making gel media, inoculating petri dishes, and generally moving liquids around between test tubes. Today, it is possible to run a number of “standard biology protocols” in the cloud, and one could conceivably spend most of their time focusing on the high-brow experiment design and analysis rather than manual labor.
Imagine a near future where instead of doing experiments on real mice, we instead simulate a highly accurate mouse behavioral model. If such models turn out to be accurate, then medical science will be revolutionized overnight by virtue of researchers being able to launch massive-scale studies with billions of simulated mouse models. A single lab might be able to replicate a hundred years of mouse behavioral studies practically overnight. A scientist working on a laptop from a coffee shop might be able to design a drug, run clinical trials on it using a variety of cloud services, and get it FDA approved all from her laptop. When this happens, Fuller’s prediction will come true and it really will seem as if we can do “everything with nothing”.
Ephemeralization for Robotics
The most obvious way to ephemeralize robot learning in software is to make simulations that resemble reality as closely as possible. Simulators are not perfect - they still suffer from the reality gap and data richness problems that originally made me skeptical of iterating in simulation. But, having worked on general purpose robots directly in the real world, I now believe that people who want high-growth careers should actively seek workflows with highest leverage, even if it means putting in the legwork to make a simulation as close to reality as possible.
There may be ways to ephemeralize robotic evaluation without having to painstakingly hand-design Rubik’s cubes and human behavior into your physics engine. One solution is to use machine learning to learn world models from data, and having the policy interact with the world model instead of the real world for evaluation. If learning high-dimensional generative models is too hard, there are off-policy evaluation methods and offline hyperparameter selection methods that don’t necessarily require simulation infrastructure. The basic intuition is that if you have a value function for a good policy, you can use it to score other policies on your real world validation datasets. The downside to these methods is that they often require finding good policy or value function to begin with, and are only accurate for ranking policies up to the level of the aforementioned policy itself. A Q(s,a) function for a policy with a 70% success rate can tell you if your new model is performing around 70% or 30% , but is not effective at telling you whether you will get 95% (since these models don’t know what they don’t know). Some preliminary research suggests that extrapolation can be possible, but it has not yet been demonstrated at the scale of evaluating general-purpose robots on millions of different conditions.
What are some alternatives to more realistic simulators? Much like the “lab in the cloud” business, there are some emerging cloud-hosted benchmarks such as AI2Thor and MPI’s Real Robot Challenge, where researchers can simply upload their code and get back results. The robot cloud provider handles all of the operational aspects of physical robots, freeing the researcher to focus on software.
One drawback of these setups is that these hosted platforms are designed for repeatable, resettable experiments, and do not have the diversity that general purpose robots would be exposed to.
Alternatively, one could follow the Tesla Autopilot approach and deploy their research code in “shadow mode” across a fleet of robots in the real world, where the model only makes predictions but does not make control decisions. This exposes evaluation to high-diversity data that cloud benchmarks don’t have, but suffers from the long-term credit assignment problem. How do we know whether a predicted action is good or not if the agent isn’t allowed to take those actions?
For these reasons, I think data-driven realistic simulation gets the best of both worlds - you get the benefits of real world diverse data and the ability to evaluate simulated long-term outcomes. Even if you are relying heavily on real-world evaluations via a hosted cloud robotics lab or a fleet running Shadow Mode, having a complementary software-only evaluation provides additional signal can only help with saving costs and time.
I suspect that a practical middle ground is to combine multiple signals from offline metrics to predict success rate: leveraging simulation to measure success rates, training world models or value functions to help predict what will happen in “imagined rollouts”, adapting simulation images to real-like data with GANs, and using old-fashioned data science techniques (logistic regression) to study the correlations between these offline metrics and real evaluated success. As we build more general AI systems that interact with the real world, I predict that there will be cottage industries dedicated to building simulators dedicated for sim2real evaluation and data scientists who build bespoke models for guessing the result of expensive real-world evaluations.
Separately from how ephemeralization drives down the cost of evaluating robots in the real world, there is the effect of ephemeralization driving down the cost of robot hardware itself. It used to be that robotics labs could only afford a couple expensive robot arms from Kuka and Franka. Each robot would cost hundreds of thousands of dollars, because they had precisely engineered encoders and motors that enabled millimeter-level precision. Nowadays, you can buy some cheap servos from AliExpress.com for a few hundred dollars, glue it to some metal plates, and control it in a closed-loop manner using a webcam and a neural network running on a laptop.
Instead of relying on hardware precise position control, the arm moves based purely on vision and hand-eye coordination. All the complexity has been migrated from hardware to software (and machine learning). This technology is not mature enough yet for factories and automotive companies to replace their precision machines with cheap servos, but the writing is on the wall: software is coming for hardware, and this trend will only accelerate.













































{kind=link}