This post is a tutorial on a few variance reduction techniques that can be used to reduce the noisiness of your estimators: antithetic sampling, control variates, and stratified sampling.
Code on Github
The Problem
Our goal is to find the expected value of the random variable $X$:
$$X = f(u) = \exp(\sin(8 u_1^2 + 3 u_1)+ \sin(11 u_2))$$
where $u$ is a 2D point sampled uniformly from the unit square, as shown below:
f(x,y) = exp(sin(8x.^2+3x)+sin(11y))
plot(linspace(0,1,100),linspace(0,1,100),f,st=:contourf,title="f(X)",size=(400,400))

The expectation can be re-written as an integral over the unit square.
\mathbb{E}[X] = \int_0^1 \int_0^1 \exp(\sin(8 u_1^2 + 3 u_1)+ \sin(11 u_2)) du_1 du_2
$$
Monte Carlo is useful in scenarios where a closed-form integral does not exist, or we do not have access to the analytical form of the function (for example, it could be a black box program that the NSA hands to us). In this case we can integrate it analytically, but let's pretend we can't :)
Basic Monte Carlo Estimator
The basic Monte Carlo estimator $\hat{\mu}$ gives a straightforward answer: "evaluate $x_i=f(u_i)$ at $n$ random values of $U$, and then take the average among all your samples." (to make comparison easier with the estimators I will introduce later on, I use $2n$ samples instead of $n$).
$$
\hat{\mu} = \frac{1}{2n}\sum_i^{2n} x_i \approx \mathbb{E}[X]
$$
Here is the estimator in code :
The plot below shows 100 samples and their values, colored according to the value of $f(X)$ at that location.

The variance of this (2n-sample) estimator is given by:
function plainMC(N)
u1 = rand(2*N)
u2 = rand(2*N)
return u1,u2,f(u1,u2),[]
end
The plot below shows 100 samples and their values, colored according to the value of $f(X)$ at that location.
u1,u2,x,ii=plainMC(N)
scatter(u1,u2,markercolor=x,
xlabel="u1",ylabel="u2",
title="Plain MC Samples",
size=(400,400),label="")

$$
\newcommand{\Var}{\operatorname{Var}}
\begin{align*}
\Var[\hat{\mu}] & = \Var[ \frac{1}{2n}\sum_i^{2n} X_i ] \\
& = (\frac{1}{2n})^2\sum_i^{2n} \Var [X_i] \\
& = \frac{\sigma^2}{2n}
\end{align*}
$$
Where $\sigma^2$ is the variance of a single sample $X_i$ and $n$ is the total number of samples.
The variance of our estimator is $\mathbb{E}[(\hat{\mu}-\mu)^2]$, or in other words, the "expected squared error" with respect to the true expectation $\mu$.

We could decrease variance by simply cranking up our sample count $n$, but this is computationally expensive. While variance is proportional to $\frac{1}{n}$, the standard deviation (which has the same units as $\mu$ and is proportional to the confidence interval of our estimator) decreases at $\frac{1}{\sqrt{n}}$, a far slower rate. This is highly unsatisfactory.
Instead, we will use variance reduction techniques to construct estimators with the same expected value as our MC estimator, and still achieve a lower variance with the same number of samples.
Antithetic Sampling
Antithetic sampling is a slight extension to the basic Monte Carlo estimator. The idea is to pair each sample $X_i$ with an "antithetic sample" $Y_i$ such that $X_i$ and $Y_i$ are identically distributed, but negatively correlated. Our single-sample estimate is given by:
$$
\hat{\mu} = \frac{X_i + Y_i}{2}
$$
$\mathbb{E}[X_i] = \mathbb{E}[Y_i]$ so this estimator has the same expected value as the plain MC estimator.
$$
\begin{align*}
\Var[\hat{\mu}] & = \frac{1}{4}\Var[X_i + Y_i] \\
& = \frac{1}{4}(\Var[X_i] + \Var[Y_i] + 2 \text{Cov}(X_i,Y_i)) && \Var[X_i] = \Var[Y_i] = \sigma^2 \\
& = \frac{1}{2}(\sigma^2 + \sigma^2\beta) && \beta = \text{Corr}(X_i,Y_i) = \frac{\text{Cov}(X_i,Y_i)}{\sigma^2}
\end{align*}
$$
If we sample $N$ of these pairs (for a total of $2N$ samples), the variance is $\frac{1}{2n}(\sigma^2 + \sigma^2\beta)$, and it's easy to see that this estimator has a strictly lower variance than the plain Monte Carlo as long as $\beta$ is negative.
Unfortunately, there isn't a general method for generating good antithetic samples. If the random sample of interest $X_i = f(U_i)$ is a transformation of a uniform random variable $U_i \sim \text{Uniform}(0,1)$, we can try "flipping" the input and letting $Y_i = f(1-U_i)$. $1-U_i$ is distributed identically to $U_i$, and assuming $f(U_i)$ is monotonic, then $Y_i$ will be large when $X_i$ is small, and vice versa.
However, this monotonicity assumption does not hold in general for 2D functions. In fact, for our choice of $f(U)$, it is only slightly negatively correlated ($\beta \approx -0.07$).
function antithetic(N)
u1_x = rand(N); u2_x = rand(N);
u1_y = 1-u1_x; u2_y = 1-u2_x;
x = f(u1_x,u2_x);
y = f(u1_y,u2_y);
return [u1_x; u1_y], [u2_x; u2_y], [x;y], (u1_x,u2_x,x,u1_y,u2_y,y)
end
Notice how each $X_i$ sample ("+") is paired with an antithetic sample $Y_i$ ("x") mirrored across the origin.
u1,u2,x,ii=antithetic(N)
u1_x,u2_x,x,u1_y,u2_y,y = ii
scatter(u1_x,u2_x,
m=(10,:cross),markercolor=x,
size=(400,400),label="X samples",
xlabel="u1",ylabel="u2",title="Antithetic Sampling")
scatter!(u1_y,u2_y,
m=(10,:xcross),markercolor=y,
label="antithetic samples")


Control Variates
Control Variates is similar to Antithetic Sampling, in that we will be pairing every sample $X_i$ with a sample of $Y_i$ (the "control variate"), and exploiting correlations between $X_i$ and $Y_i$ in order to decrease variance.
However, $Y_i$ is no longer sampled from the same distribution as $X_i$. Typically $Y_i$ is some random variable that is computationally easy to generate (or is generated as a side effect) from the generative process for $X_i$. For instance, the weather report that forecasts temperature $X$ also happens to predict rainfall $Y$. We can use rainfall measurements $Y_i$ to improve our estimates of "average temperature" $\mathbb{E}[X]$.
Suppose control variate $Y$ has a known expected value $\bar{\mu}$. The single-sample estimator is given by
$$
\hat{\mu} = X_i - c (Y_i - \mathbb{E}[Y_i])
$$
Where $c$ is some constant. In expectation, $Y_i$ samples are cancelled out by $\bar{\mu}$ so this estimator is unbiased.
It's variance is
$$
\begin{align*}
\Var[\hat{\mu}] & = \Var[X_i - c (Y_i - \mathbb{E}[Y_i])] \\
& = \Var[X_i - c Y_i] && \mathbb{E}[Y_i] \text{ is not random, and has zero variance} \\
& = \Var[X_i] + c^2 \Var[Y_i] + 2cCov(X_i,Y_i)
\end{align*}
$$
Simple calculus tells us that the value of $c$ that minimizes $Var[\hat{\mu}]$ is
$$
c^* = -\frac{Cov(X_i,Y_i)}{\Var(Y_i)}
$$
so the best variance we can achieve is
$$
\Var[\hat{\mu}] = \Var[X_i] - \frac{Cov(X_i,Y_i)^2}{\Var(Y_i)}
$$
The variance of our estimator is reduced as long as $Cov(X_i,Y_i)^2 \neq 0$. Unlike antithetic sampling, control variates can be either positively or negatively correlated with $X_i$.
The catch here is that $c^*$ will need to be estimated. There are a couple ways:
- Forget optimality, just let $c^* = 1$! This naive approach still works better than basic Monte Carlo because it exploits covariance structure.
- Estimate $c^*$ from samples $X_i$, $Y_i$. Doing so introduces a dependence between $c^*$ and $Y_i$, which makes the estimator biased, but in practice this bias is small compared to the standard error of the estimate.
- An unbiased alternative to (2) is to compute $c^*$ from a small set of $m < n$ "pilot samples", and then throw the pilot samples away before collecting the real $n$ samples.
In the case of our $f(u)$, we know that the modes of the distribution are scattered in the corners of the unit square. In polar coordinates centered at $(0.5,0.5)$, that's about $k \frac{\pi}{2} + \frac{\pi}{4}, k=0,1,2,3$. Let's choose $Y = -cos(4\theta)$, where $\theta$ is uniform about the unit circle.
cv(u1,u2) = -cos(4*atan((u2-.5)./(u1-.5)))
pcv = plot(linspace(0,1,100),linspace(0,1,100),cv,st=:contourf,title="Y",xlabel="u1",ylabel="u2")
plot(pcv,p0,layout=2)

$$
\begin{align*}
\mathbb{E}_U[Y] & = \int_0^1 \int_0^1 -\cos(4\theta) du_1 du_2 \\
& = \int_0^1 \int_0^1 - \frac{1-\tan^2(2\theta)}{1+\tan^2(2\theta)} du_1 du_2 \\
& = \int_0^1 \int_0^1 - \frac{1-(\frac{2\tan \theta}{1 - \tan^2(\theta)})^2}{1+(\frac{2\tan \theta}{1 - \tan^2(\theta)})^2} du_1 du_2 && \tan(\theta) = \frac{y}{x} \\
& = \pi-3
\end{align*}
$$
In practice though, we don't have an analytic way to compute $E[Y]$, but we can estimate it in an unbiased manner from our pilot samples.
function controlvariates(N)
# generate pilot samples
npilot = 30
u1 = rand(npilot); u2 = rand(npilot)
x = f(u1,u2)
y = cv(u1,u2)
β=corr(x,y)
c = -β/var(y)
μ_y = mean(y) # estimate mean from pilot samples
# real samples
u1 = rand(2*N); u2 = rand(2*N)
x = f(u1,u2)
y = cv(u1,u2)
return u1,u2,x+c*(y-μ_y),(μ_y, β, c)
end
We can verify from our pilot samples that the covariance is quite large:
The idea behind stratified sampling is very simple: instead of estimating $E[X]$ over the domain $U$, we break up the domain into $K$ strata, estimate the conditional expectation $X$ over each strata separately, then average our per-strata estimates.

In the above picture, the sample space is divided into 50 strata going across the horizontal axis and there are 2 points placed in each strata. There are lots of ways to stratify - you can stratify in a 1D grid, 2D grid, concentric circles with varying areas, whatever you like.
We're not restricted to chopping up $U$ into little fiefdoms as above (although it is a natural choice). Instead, we introduce a "stratification variable" $Y$ with discrete values $y_1,...,y_k$. Our estimators for each strata correspond to the conditional expectations $\mathbb{E}[X|Y=y_i] \text{ for } i=1...K$.
The estimator is given by a weighted combination of strata estimates with the respective probability of each strata:
$$
\hat{mu} = \sum_i^k p(y_i) \mathbb{E}[X|Y=y_i]
$$
The variance of this estimator is
$$
\sum_i^k p(y_i)^2 (V_i)
$$
Where $V_i$ is the variance of estimator $i$.
For simplicity, let's assume:
Then the variance is
$$
\sum_i^k (\frac{1}{k} p(y_i)) (\frac{k}{2n}\sigma_i^2) = \frac{1}{2n} \sum_i^k p(y_i) \sigma_i^2 \leq \frac{1}{2n} \sigma^2
$$
Intuitively, the variance within a single grid cell $\sigma_i^2$ should be smaller than the variance of the plain MC estimator, because samples are closer together.
Here's a proof that $\sum_i^k p(y_i)\sigma_i^2 \leq \sigma^2$:
Let $\mu_i = \mathbb{E}[X|Y=y_i], \sigma_i^2 = \Var[X|Y]$
$$
\begin{align*}
\mathbb{E}[X^2] & = \mathbb{E}_Y[\mathbb{E}_X[X^2|Y]] && \text{Tower property} \\
& = \sum_i^k p(y_i) \mathbb{E}[X^2|Y=y_i] \\
& = \sum_i^k p(y_i) (\sigma_i^2 + \mu_i^2) && \text{via } \Var[X|Y] = \mathbb{E}[X^2|Y] - \mathbb{E}[X|Y=y_i]^2 \\
\mathbb{E}[X] & = \mathbb{E}_Y[\mathbb{E}_X[X|Y]] \\
& =\sum_i^k p(y_i) \mu_i \\
\sigma^2 & = \mathbb{E}[X^2] - \mathbb{E}[X]^2 \\
& =\sum_i^k p(y_i) \sigma_i^2 + \big[\sum_i^k p(y_i) \mu_i^2 - (\sum_i^k p(y_i) \mu_i)^2\big]
\end{align*}
$$
Note that the term
$$
\sum_i^k p(y_i) \mu_i^2 - (\sum_i^k p(y_i) \mu_i)^2
$$
corresponds to the variance of a categorical distribution that takes value $\mu_i$ with probability $p(y_i)$. This term is strictly non-negative, and therefore the inequality $\sum_i^k \frac{k}{2n}\sigma_i^2 \leq \sigma^2$ holds.
This yields an interesting observation: when we do stratified sampling, we are eliminating the variance between strata means. This implies that we get the most gains by choosing strata such that samples vary greatly between strata.
Here's a comparison of the empirical vs. theoretical variance with respect to number of strata:

Remarks:
Here's a plot comparing the standard deviations of these estimators as a function of sample size. Keep in mind that your choice of variance reduction technique should depend on the problem, and no method is objectively better than the others. This is a very simple toy problem so all estimators perform pretty well.

A toy example is all well and good, but where does variance reduction come up in modern scientific computing?
At a very fundamental level, variance in scientific data either suggests an underlying noisy process or errors. Variance degrades the statistical significance of findings, so it's desirable to conduct experiments and measurements such that the variance of findings is low.
In finance, we often simulate expected returns of portfolios by sampling over all possible movements in the market. Certain rare events (for example, a terrorist attack) are highly unlikely but have such a big impact that on the economy that we want to account for it in our expectation. Modeling these "black swan" events are of considerable interest to financial & actuarial industries.
In minibatch stochastic gradient descent (the "hammer" of Deep Learning), we compute the parameter update using the expected gradient of the total loss across the training dataset. It takes too long to consider every point in the dataset, so we estimate gradients via stochastic minibatch. This is nothing more than a Monte Carlo estimate.
In physically based rendering, we are trying to compute the total incoming light arriving at each camera pixel. The vast majority of paths contribute zero radiance, thus making our samples noisy. Decreasing variance allows us to "de-speckle" the pictures.
$$
\begin{align*}
\mathcal{L}(x,\omega_o) & = \mathcal{L}_e(x,\omega_o) + \int_\Omega{f_r(x,\omega_i,\omega_o)\mathcal{L}(x^\prime,\omega_i)(\omega_o \cdot n_x) d\omega_i} \\
& \approx \mathcal{L}_e(x,\omega_o) + \frac{1}{m}\sum_i^m{f_r(x,\omega_i,\omega_o)\mathcal{L}(x^\prime,\omega_i)(\omega_o \cdot n_x)}
\end{align*}
$$

βs=[]
for i=1:1000
u1,u2,x,ii=controlvariates(100)
βs = [βs; ii[2]]
end
mean(βs) # 0.367405
Stratified Sampling
The idea behind stratified sampling is very simple: instead of estimating $E[X]$ over the domain $U$, we break up the domain into $K$ strata, estimate the conditional expectation $X$ over each strata separately, then average our per-strata estimates.
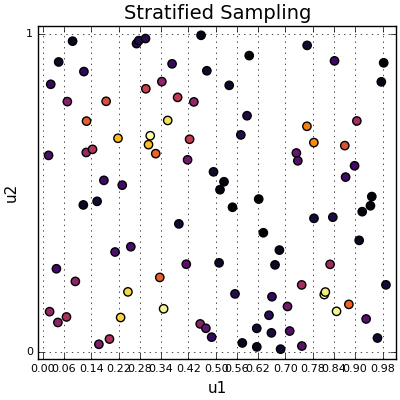
In the above picture, the sample space is divided into 50 strata going across the horizontal axis and there are 2 points placed in each strata. There are lots of ways to stratify - you can stratify in a 1D grid, 2D grid, concentric circles with varying areas, whatever you like.
We're not restricted to chopping up $U$ into little fiefdoms as above (although it is a natural choice). Instead, we introduce a "stratification variable" $Y$ with discrete values $y_1,...,y_k$. Our estimators for each strata correspond to the conditional expectations $\mathbb{E}[X|Y=y_i] \text{ for } i=1...K$.
The estimator is given by a weighted combination of strata estimates with the respective probability of each strata:
function stratified(N)
# N strata, 2 samples per strata = 2N samples
u1 = Float64[]
u2 = Float64[]
for y=range(0,1/N,N)
for i=1:2
append!(u1,[y+1/N*rand()])
append!(u2,[rand()])
end
end
return u1,u2,f(u1,u2),[]
end
$$
\hat{mu} = \sum_i^k p(y_i) \mathbb{E}[X|Y=y_i]
$$
The variance of this estimator is
$$
\sum_i^k p(y_i)^2 (V_i)
$$
Where $V_i$ is the variance of estimator $i$.
For simplicity, let's assume:
- We stratify along an evenly-spaced grid, i.e. $p(y_i) = \frac{1}{k}$
- We are using a simple MC estimator within each strata, $V_i = \frac{\sigma_i^2}{n_i}$, with $n_i = \frac{2n}{k}$ samples each (so the total number of samples is $2n$, the same as the plain MC estimator). $\sigma_i^2$ is the variance of an individual sample within each strata.
Then the variance is
$$
\sum_i^k (\frac{1}{k} p(y_i)) (\frac{k}{2n}\sigma_i^2) = \frac{1}{2n} \sum_i^k p(y_i) \sigma_i^2 \leq \frac{1}{2n} \sigma^2
$$
Intuitively, the variance within a single grid cell $\sigma_i^2$ should be smaller than the variance of the plain MC estimator, because samples are closer together.
Here's a proof that $\sum_i^k p(y_i)\sigma_i^2 \leq \sigma^2$:
Let $\mu_i = \mathbb{E}[X|Y=y_i], \sigma_i^2 = \Var[X|Y]$
$$
\begin{align*}
\mathbb{E}[X^2] & = \mathbb{E}_Y[\mathbb{E}_X[X^2|Y]] && \text{Tower property} \\
& = \sum_i^k p(y_i) \mathbb{E}[X^2|Y=y_i] \\
& = \sum_i^k p(y_i) (\sigma_i^2 + \mu_i^2) && \text{via } \Var[X|Y] = \mathbb{E}[X^2|Y] - \mathbb{E}[X|Y=y_i]^2 \\
\mathbb{E}[X] & = \mathbb{E}_Y[\mathbb{E}_X[X|Y]] \\
& =\sum_i^k p(y_i) \mu_i \\
\sigma^2 & = \mathbb{E}[X^2] - \mathbb{E}[X]^2 \\
& =\sum_i^k p(y_i) \sigma_i^2 + \big[\sum_i^k p(y_i) \mu_i^2 - (\sum_i^k p(y_i) \mu_i)^2\big]
\end{align*}
$$
Note that the term
$$
\sum_i^k p(y_i) \mu_i^2 - (\sum_i^k p(y_i) \mu_i)^2
$$
corresponds to the variance of a categorical distribution that takes value $\mu_i$ with probability $p(y_i)$. This term is strictly non-negative, and therefore the inequality $\sum_i^k \frac{k}{2n}\sigma_i^2 \leq \sigma^2$ holds.
This yields an interesting observation: when we do stratified sampling, we are eliminating the variance between strata means. This implies that we get the most gains by choosing strata such that samples vary greatly between strata.
Here's a comparison of the empirical vs. theoretical variance with respect to number of strata:
# theoretical variance
strat_var = zeros(50)
for N=1:50
sigma_i_2 = zeros(N)
y = range(0,1/N,N)
for i=1:N
x1 = y[i].+1/N*rand(100)
x2 = rand(100)
sigma_i_2[i]=var(f(x1,x2))
end
n_i = 2
strat_var[N] = sum((1/(N))^2*(1/n_i*sigma_i_2))
end
s = estimatorVar(stratified)
plot(1:50,s,label="Empirical Variance",title="Stratified Sampling")
plot!(1:50,strat_var,label="Theoretical Variance")

Remarks:
- Stratified Sampling can actually be combined with other variance reduction techniques - for instance, when computing the conditional estimate within a strata, you are free to use antithetic sampling, control variates within the strata. You can even do stratified sampling within your strata! This makes sense if your sampling domain is already partitioned into a bounding volume hierarchy, such as a KD-Tree.
- Antithetic sampling can be regarded as a special case of stratified sampling with 2 strata. The inter-strata variance you are eliminating here is the self-symmetry in the distribution of $X$ (the covariance between one half and another half of the samples).
Discussion
Here's a plot comparing the standard deviations of these estimators as a function of sample size. Keep in mind that your choice of variance reduction technique should depend on the problem, and no method is objectively better than the others. This is a very simple toy problem so all estimators perform pretty well.

I'm currently working on a follow-up tutorial on Importance Sampling. The explanation is a bit long, so I'm keeping it separate from this tutorial.
A toy example is all well and good, but where does variance reduction come up in modern scientific computing?
Scientific Data Analysis
At a very fundamental level, variance in scientific data either suggests an underlying noisy process or errors. Variance degrades the statistical significance of findings, so it's desirable to conduct experiments and measurements such that the variance of findings is low.
Quantitative Finance
In finance, we often simulate expected returns of portfolios by sampling over all possible movements in the market. Certain rare events (for example, a terrorist attack) are highly unlikely but have such a big impact that on the economy that we want to account for it in our expectation. Modeling these "black swan" events are of considerable interest to financial & actuarial industries.

Deep Learning
In minibatch stochastic gradient descent (the "hammer" of Deep Learning), we compute the parameter update using the expected gradient of the total loss across the training dataset. It takes too long to consider every point in the dataset, so we estimate gradients via stochastic minibatch. This is nothing more than a Monte Carlo estimate.
$$E_x[\nabla_\theta J(x;\theta)] = \int p(x) \nabla_\theta J(x;\theta) dx \approx \frac{1}{m}\sum_i^m \nabla_\theta J(x_i;\theta)$$
The less variance we have, the sooner our training converges.
Computer Graphics
In physically based rendering, we are trying to compute the total incoming light arriving at each camera pixel. The vast majority of paths contribute zero radiance, thus making our samples noisy. Decreasing variance allows us to "de-speckle" the pictures.
$$
\begin{align*}
\mathcal{L}(x,\omega_o) & = \mathcal{L}_e(x,\omega_o) + \int_\Omega{f_r(x,\omega_i,\omega_o)\mathcal{L}(x^\prime,\omega_i)(\omega_o \cdot n_x) d\omega_i} \\
& \approx \mathcal{L}_e(x,\omega_o) + \frac{1}{m}\sum_i^m{f_r(x,\omega_i,\omega_o)\mathcal{L}(x^\prime,\omega_i)(\omega_o \cdot n_x)}
\end{align*}
$$

All the data analysis methods should have some common procedure to find out the right value of the variance.The carco system should be learned by many of the people who want to get the chance.The www.delishibusiness.com is knowing the appropriate for the develpment of the community where the people can improve their thinking regarding the 2D ND 3D graphics design.
ReplyDeleteMath is the hard thing for me. I was disappointed since I study it. I'm sure I could be a great writer, I even write my first book, it is edited at https://help.plagtracker.com/book-editing.html. Book editing helps me a lot. Anyways, thanks for explanation these equals.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteHi Eric, I believ you've got a typo in the control variate derivation. It should be:
ReplyDelete\hat{\mu} = X_i + c (Y_i - \mathbb{E}[Y_i])
Otherwise you'd have a minus for the value of c.
I agree there is a typo, but not in the equation you mentioned. I think the negative should be in step 3 after expanding the variance, so 2cCov(X_i,Y_i) should be -2cCov(X_i,Y_i) and c* becomes a positive quotient. The rest of the derivation should remain the same.
DeleteIts to much informative we are also provide online education and also provide online professional work degree, check it Pacific Cambria University Website just enroll and some simple step to take your work experience degree.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteYeah, I absolutelly agree with you, when I was a student it was really hard, because I was working to pay my education. I even bought here coursework writing service some of my college essays, cuz I didnt have enough time to write them by myself.
ReplyDelete