The exercise was partially successful. Maybe. I still don't think she knows what Deep Learning is, besides that I am a big fan of it and use it for my job.
 |
| I'm a big fan of Deep Learning |
This post is a slightly more technical version of the explanation I gave my mom, with the hope that it will help Deep Learning practitioners to better understand what is going on in neural networks.
If you are getting started into Deep Learning research, you may discover that there are a whole bunch of seemingly arbitrary techniques used to train neural networks, with very little theoretical justification besides "it works". For example: dropout regularization, adding gradient noise,, asynchronous stochastic descent.
What do all these hocus pocus techniques have in common? They incorporate randomness!

Random noise actually is crucial for getting DNNs to work well:
- Random noise allows neural nets to produce multiple outputs given the same instance of input.
- Random noise limits the amount of information flowing through the network, forcing the network to learn meaningful representations of data.
- Random noise provides "exploration energy" for finding better optimization solutions during gradient descent.
Single Input, Multiple Output
Suppose you are training a deep neural network (DNN) to classify images.

For each cropped region, the network learns to convert an image into a number representing a class label, such as “dog” or "person".
That’s all very well and good, and these kind of DNNs do not require randomness in their inference model. After all, any image of a dog should be mapped to the “dog” label, and there is nothing random about that.
Now suppose you are training a deep neural network (DNN) to play Go (game). In the case of the image below, the DNN has to make the first move.
That’s all very well and good, and these kind of DNNs do not require randomness in their inference model. After all, any image of a dog should be mapped to the “dog” label, and there is nothing random about that.
Now suppose you are training a deep neural network (DNN) to play Go (game). In the case of the image below, the DNN has to make the first move.
If you used the same deterministic strategy described above, you will find that this network fails to give good results. Why? Because there is no single “optimal starting move” - for each possible stone placement on the board, there is a equally good stone placement on the other side board, via rotational symmetry. There are multiple best answers.
If the network is deterministic and only capable of picking one output per input, then the optimization process will force the network to choose the move that averages all the best answers, which is smack-dab in the middle of the board. This behavior is highly undesirable, as the center of the board is generally regarded as a bad starting move.
Hence, randomness is important when you want the network to be able to output multiple possibilities given the same input, rather than generating the same output over and over again. This is crucial when there are underlying symmetries in the action space - incorporating randomness literally helps us break out of the "stuck between two bales of hay" scenario.
Similarly, if we are training a neural net to compose music or draw pictures, we don’t want it to always draw the same thing or play the same music every time it is given a blank sheet of paper. We want some notion of “variation”, "surprise", and “creativity” in our generative models.
One approach to incorporating randomness into DNNs is to keep the network deterministic, but have its outputs be the parameters of a probability distribution, which we can then draw samples from using conventional sampling methods to generate “stochastic outputs”.
Deepmind's AlphaGo utilized this principle: given an image of a Go board, it outputs the probability of winning given each possible move. The practice of modeling a distribution after the output of the network is commonly used in other areas of Deep Reinforcement Learning.
During my first few courses in probability & statistics, I really struggled to understand the physical meaning of randomness. When you flip a coin, where does this randomness come from? Is randomness just deterministic chaos? Is it possible for something to be actually random?

Information theory offers a definition of randomness that is grounded enough to use without being kept wide awake at night: "randomness" is nothing more than the "lack of information".
More specifically, the amount of information in an object is the length (e.g. in bits, kilobytes, etc.) of the shortest computer program needed to fully describe it. For example, the first 1 million digits of $\pi = 3.14159265....$ can be represented as a string of length 1,000,002 characters, but it can be more compactly represented using 70 characters, via an implementation of the Leibniz Formula:
The above program is nothing more than a compressed version of a million digits of $\pi$. A more concise program could probably express the first million digits of $\pi$ in far fewer bits.
Under this interpretation, randomness is "that which cannot be compressed". While the first million digits of $\pi$ can be compressed and are thus not random, empirical evidence suggests (but has not proven) that $\pi$ itself is normal number, and thus the amount of information encoded in $\pi$ is infinite.
Consider a number $a$ that is equal to the first trillion digits of $\pi$, $a = 3.14159265...$. If we add to that a uniform random number $r$ that lies in the range $(-0.001,0.001)$, we get a number that ranges in between $3.14059...$ and $3.14259...$. The resulting number $a + r$ now only carries ~three digits worth of information, because the process of adding random noise destroyed any information carried after the hundredth's decimal place.
What does this definition of randomness have to deal with randomness?
Another way randomness is incorporated into DNNs is by injecting noise directly into the network itself, rather than using the DNN to model a distribution. This makes the task "harder" to learn as the network has to overcome these internal "perturbations".
Why on Earth would you want to do this? The basic intuition is that noise limits the amount of information you can pass through a channel.
Consider an autoencoder, a type of neural network architecture that attempts to learn an efficient encoding of data by "squeezing" the input into fewer dimensions in the middle and re-constituting the original data at the other end. A diagram is shown below:

During inference, inputs flow from the left through the nodes of the network and come out the other side, just like a pipe.
If we consider a theoretical neural network that operates on real numbers (rather than floating point numbers), then without noise in the network, every layer of the DNN actually has access to infinite information bandwidth.
Even though we are squeezing representations (the pipe) into fewer hidden units, the network could still learn to encode the previous layer's data into the decimal point values without actually learning any meaningful features. In fact, we could represent all the information in the network with a single number. This is undesirable.
By limiting the amount of information in a network, we force it to learn compact representations of input features. Several ways to go about this:
DNNs are usually trained via some variant of gradient descent, which basically amounts to finding the parameter update that "rolls downhill" along some loss function. When you get to the bottom of the deepest valley, you've found the best possible parameters for your neural net.
The problem with this approach is that neural network loss surfaces have a lot of local minima and plateaus. It's easy to get stuck in a small dip or a flat portion where the slope is already zero (local minima) but you are not done yet.

The third interpretation of how randomness assists Deep Learning models is based on the idea of the exploration.
Because the datasets used to train DNNs are huge, it’s too expensive to compute the gradient across terabytes of data for every single gradient descent step. Instead, we use stochastic gradient descent (SGD), where we just compute the average gradient across a small subset of the dataset chosen randomly from the dataset.
In evolution, if the success of a species is modeled by random variable $X$, then random mutation or noise increases the variance of $X$ - its progeny could either be far better off (adaptation, poison defense) or far worse off (lethal defects, sterility).
In numerical optimization, this "genetic mutability" is called "thermodynamic energy", or Temperature that allows the parameter update trajectory to not always "roll downhill", but occasionally bounce out of a local minima or "tunnel through" hills.
This is all deeply related to the Exploration-vs.-Exploitation tradeoff as formulated in RL. Training a purely deterministic DNN with zero gradient noise has zero exploitation capabilities - it converges straight to the nearest local minima, however shallow.
Using stochastic gradients (either via small minibatches or literally adding noise to the gradients themselves) is an effective way to allow the optimization to do a bit of "searching" and "bouncing" out of weak local minima. Asynchronous stochastic gradient descent, in which many machines are performing gradient descent in parallel, is another possible source of noise.
This "thermodynamic" energy ensures symmetry-breaking during early stages of training, to ensure that all the gradients in a layer are not synchronized to the same values. Not only does noise perform symmetry breaking in action space of the neural net, but noise also performs symmetry breaking in the parameter space of the neural net.
If the network is deterministic and only capable of picking one output per input, then the optimization process will force the network to choose the move that averages all the best answers, which is smack-dab in the middle of the board. This behavior is highly undesirable, as the center of the board is generally regarded as a bad starting move.
Hence, randomness is important when you want the network to be able to output multiple possibilities given the same input, rather than generating the same output over and over again. This is crucial when there are underlying symmetries in the action space - incorporating randomness literally helps us break out of the "stuck between two bales of hay" scenario.
Similarly, if we are training a neural net to compose music or draw pictures, we don’t want it to always draw the same thing or play the same music every time it is given a blank sheet of paper. We want some notion of “variation”, "surprise", and “creativity” in our generative models.
One approach to incorporating randomness into DNNs is to keep the network deterministic, but have its outputs be the parameters of a probability distribution, which we can then draw samples from using conventional sampling methods to generate “stochastic outputs”.
Deepmind's AlphaGo utilized this principle: given an image of a Go board, it outputs the probability of winning given each possible move. The practice of modeling a distribution after the output of the network is commonly used in other areas of Deep Reinforcement Learning.
Randomness and Information Theory
During my first few courses in probability & statistics, I really struggled to understand the physical meaning of randomness. When you flip a coin, where does this randomness come from? Is randomness just deterministic chaos? Is it possible for something to be actually random?
To be honest, I still don't fully understand.
Information theory offers a definition of randomness that is grounded enough to use without being kept wide awake at night: "randomness" is nothing more than the "lack of information".
More specifically, the amount of information in an object is the length (e.g. in bits, kilobytes, etc.) of the shortest computer program needed to fully describe it. For example, the first 1 million digits of $\pi = 3.14159265....$ can be represented as a string of length 1,000,002 characters, but it can be more compactly represented using 70 characters, via an implementation of the Leibniz Formula:
The above program is nothing more than a compressed version of a million digits of $\pi$. A more concise program could probably express the first million digits of $\pi$ in far fewer bits.
Under this interpretation, randomness is "that which cannot be compressed". While the first million digits of $\pi$ can be compressed and are thus not random, empirical evidence suggests (but has not proven) that $\pi$ itself is normal number, and thus the amount of information encoded in $\pi$ is infinite.
Consider a number $a$ that is equal to the first trillion digits of $\pi$, $a = 3.14159265...$. If we add to that a uniform random number $r$ that lies in the range $(-0.001,0.001)$, we get a number that ranges in between $3.14059...$ and $3.14259...$. The resulting number $a + r$ now only carries ~three digits worth of information, because the process of adding random noise destroyed any information carried after the hundredth's decimal place.
Limiting Information in Neural Nets
What does this definition of randomness have to deal with randomness?
Another way randomness is incorporated into DNNs is by injecting noise directly into the network itself, rather than using the DNN to model a distribution. This makes the task "harder" to learn as the network has to overcome these internal "perturbations".
Why on Earth would you want to do this? The basic intuition is that noise limits the amount of information you can pass through a channel.
Consider an autoencoder, a type of neural network architecture that attempts to learn an efficient encoding of data by "squeezing" the input into fewer dimensions in the middle and re-constituting the original data at the other end. A diagram is shown below:
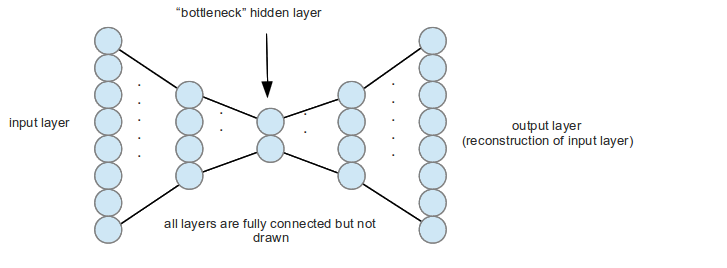
During inference, inputs flow from the left through the nodes of the network and come out the other side, just like a pipe.
If we consider a theoretical neural network that operates on real numbers (rather than floating point numbers), then without noise in the network, every layer of the DNN actually has access to infinite information bandwidth.
Even though we are squeezing representations (the pipe) into fewer hidden units, the network could still learn to encode the previous layer's data into the decimal point values without actually learning any meaningful features. In fact, we could represent all the information in the network with a single number. This is undesirable.
- Variational autoencoders (VAE) add Gaussian noise to the hidden layer. This noise destroys "excess information," forcing the network to learn compact representations of data.
- Closely related to VAE noise (possibly equivalent?) to this is the idea of Dropout Regularization - randomly zeroing out some fraction of units during training. Like the VAE, dropout noise forces the network to learn useful information under limited bandwidth.
- Deep Networks with Stochastic Depth - similar idea to dropout, but at a per-layer level rather than per-unit level.
- There's a very interesting paper called Binarized Neural Networks that uses binary weights and activations in the inference pass, but real-valued gradients in the backward pass. The source of noise comes from the fact that the gradient is a noisy version of the binarized gradient. While BinaryNets are not necessarily more powerful than regular DNNs, individual units can only encode one bit of information, which regularizes against two features being squeezed into a single unit via floating point encoding.
More efficient compression schemes mean better generalization at test-time, which explains why dropout works so well for over-fitting. If you decide to use regular autoencoders over variational autoencoders, you must use a stochastic regularization trick such as dropout to control how many bits your compressed features should be, otherwise you will likely over-fit.
I think VAEs are objectively superior because they are easy to implement and allow you to specify exactly how many bits of information are passing through each layer.
Exploration "Energy"
DNNs are usually trained via some variant of gradient descent, which basically amounts to finding the parameter update that "rolls downhill" along some loss function. When you get to the bottom of the deepest valley, you've found the best possible parameters for your neural net.
The problem with this approach is that neural network loss surfaces have a lot of local minima and plateaus. It's easy to get stuck in a small dip or a flat portion where the slope is already zero (local minima) but you are not done yet.

Because the datasets used to train DNNs are huge, it’s too expensive to compute the gradient across terabytes of data for every single gradient descent step. Instead, we use stochastic gradient descent (SGD), where we just compute the average gradient across a small subset of the dataset chosen randomly from the dataset.
In evolution, if the success of a species is modeled by random variable $X$, then random mutation or noise increases the variance of $X$ - its progeny could either be far better off (adaptation, poison defense) or far worse off (lethal defects, sterility).
In numerical optimization, this "genetic mutability" is called "thermodynamic energy", or Temperature that allows the parameter update trajectory to not always "roll downhill", but occasionally bounce out of a local minima or "tunnel through" hills.
This is all deeply related to the Exploration-vs.-Exploitation tradeoff as formulated in RL. Training a purely deterministic DNN with zero gradient noise has zero exploitation capabilities - it converges straight to the nearest local minima, however shallow.
Using stochastic gradients (either via small minibatches or literally adding noise to the gradients themselves) is an effective way to allow the optimization to do a bit of "searching" and "bouncing" out of weak local minima. Asynchronous stochastic gradient descent, in which many machines are performing gradient descent in parallel, is another possible source of noise.
This "thermodynamic" energy ensures symmetry-breaking during early stages of training, to ensure that all the gradients in a layer are not synchronized to the same values. Not only does noise perform symmetry breaking in action space of the neural net, but noise also performs symmetry breaking in the parameter space of the neural net.
Closing Thoughts
I find it really interesting that random noise actually helps Artificial Intelligence algorithms to avoid over-fitting and explore the solution space during optimization or Reinforcement Learning. It raises interesting philosophical questions on whether the inherent noisiness of our neural code is a feature, not a bug.
One theoretical ML research question I am interested in is whether all these neural network training tricks are actually variations of some general regularization theorem. Perhaps theoretical work on compression will be really useful for understanding this.
It would be interesting to check the information capacity of various neural networks relative to hand-engineered feature representations, and see how that relates to overfitting tendency or quality of gradients. It's certainly not trivial to measure the information capacity of a network with dropout or trained via SGD, but I think it can be done. For example, constructing a database of synthetic vectors whose information content (in bits, kilobytes, etc) is exactly known, and seeing how networks of various sizes, in combination with techniques like dropout, deal with learning a generative model of that dataset.
Nice article!
ReplyDeleteBut it seems like a typo: "the range (−0.01,0.01)" -> "the range (−0.001,0.001)"
Thanks for your sharp eyes :) I've made the change.
DeleteEvery time I cannot decide which of which, I just turn to any random things I can think of. Randomness for me is basically uncomplicating complicated circumstances. It's like giving you a choice but still your explanation here is so deep, I cannot but fathom but good work Eric. I might want to order research paper here instead.
ReplyDeleteAll the above-mentioned trends should be watched closely by all those who are looking forward to developing e learning content.
ReplyDeletefree learning
Randomness is actually the need of time for all industries. Deep learning has become very difficult in today’s world. Deep learning is very important for various reasons and the most important reason is that distractions like smartphones have made it difficult for people to engulf in deep learning. During a study in an online institute that offers non fake college degrees it was concluded that to engage properly in deep learning, it is important to keep away all the distractions similar to smartphones. The point is again the same that people who want to engage in deep learning, they should be fully focused and ready for it.
ReplyDelete